
Demystifying PDF Parsing 06: Representative Industry Solutions

This is the sixth article in our series. In this article, we explore how PDF parsing is performed within the well-known and popular RAG (Retrieval-Augmented Generation) framework in the industry.
This article discusses the following industrial RAG framework:
Dify
QAnything
RAGFlow
Cognita
Kotaemon
Additionally, I will summarize the key takeaways and provide my thoughts and insights.
Dify
Dify is a popular open-source LLM app development platform. Its intuitive interface combines AI workflows, RAG pipeline, agent capabilities, model management, observability features, and more. RAG pipeline is a fundamental module within Dify, as shown in Figure 1.
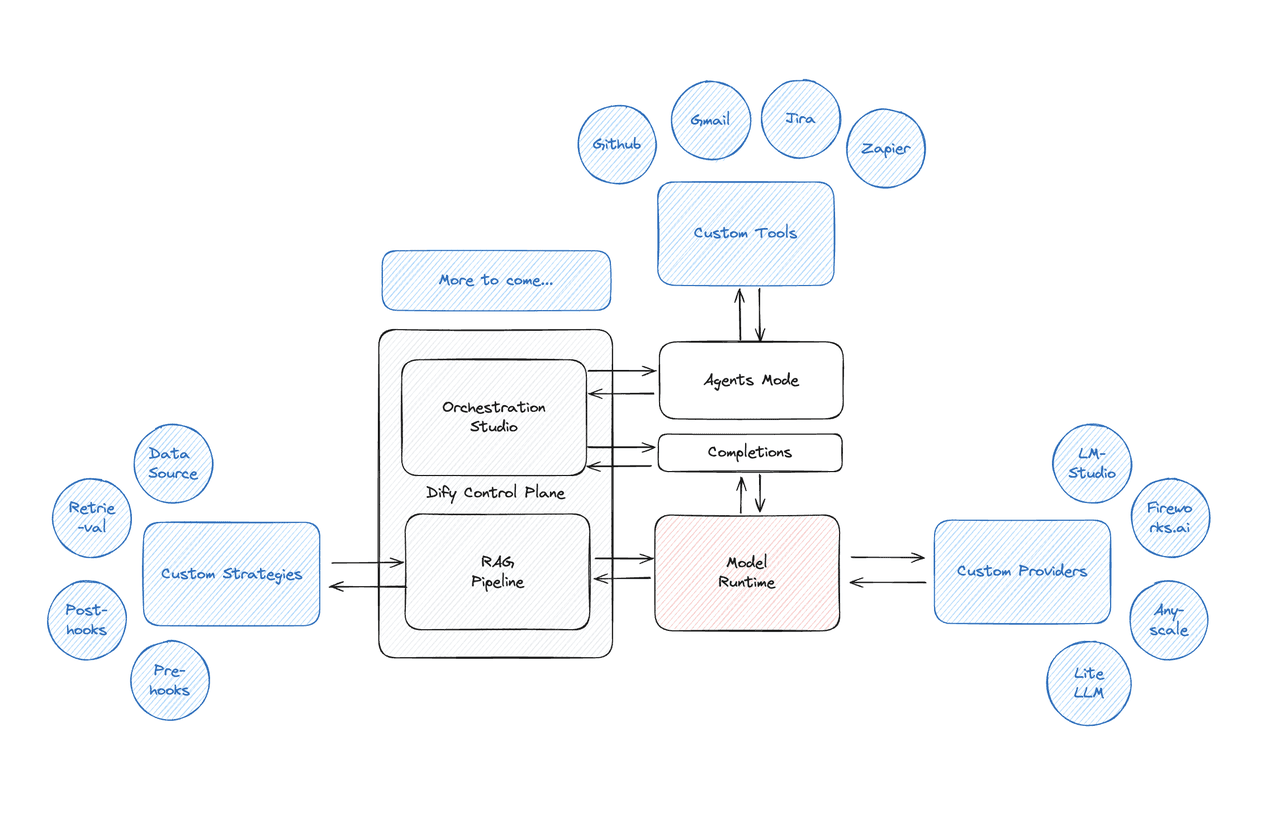
In Dify, file loading and parsing are implemented in the class ExtractProcessor. We focus particularly on the most complex PDF files among all file formats, which are handled in the class PdfExtractor, using pypdfium2 library for parsing.
def parse(self, blob: Blob) -> Iterator[Document]:
"""Lazily parse the blob."""
import pypdfium2
with blob.as_bytes_io() as file_path:
pdf_reader = pypdfium2.PdfDocument(file_path, autoclose=True)
try:
for page_number, page in enumerate(pdf_reader):
text_page = page.get_textpage()
content = text_page.get_text_range()
text_page.close()
page.close()
metadata = {"source": blob.source, "page": page_number}
yield Document(page_content=content, metadata=metadata)
finally:
pdf_reader.close()Additionally, Dify offers features to clean up content parsed from files by removing superfluous characters, correcting encoding errors, and more. These strategies are based on unstructured cleaning. Dify encapsulates various cleaning strategies into interfaces, simplifying the selection process for the application layer.
QAnything
QAnything (Question and Answer based on Anything) is a local knowledge base question-answering system designed to support a wide range of file formats and databases. Its architecture is shown in Figure 2.
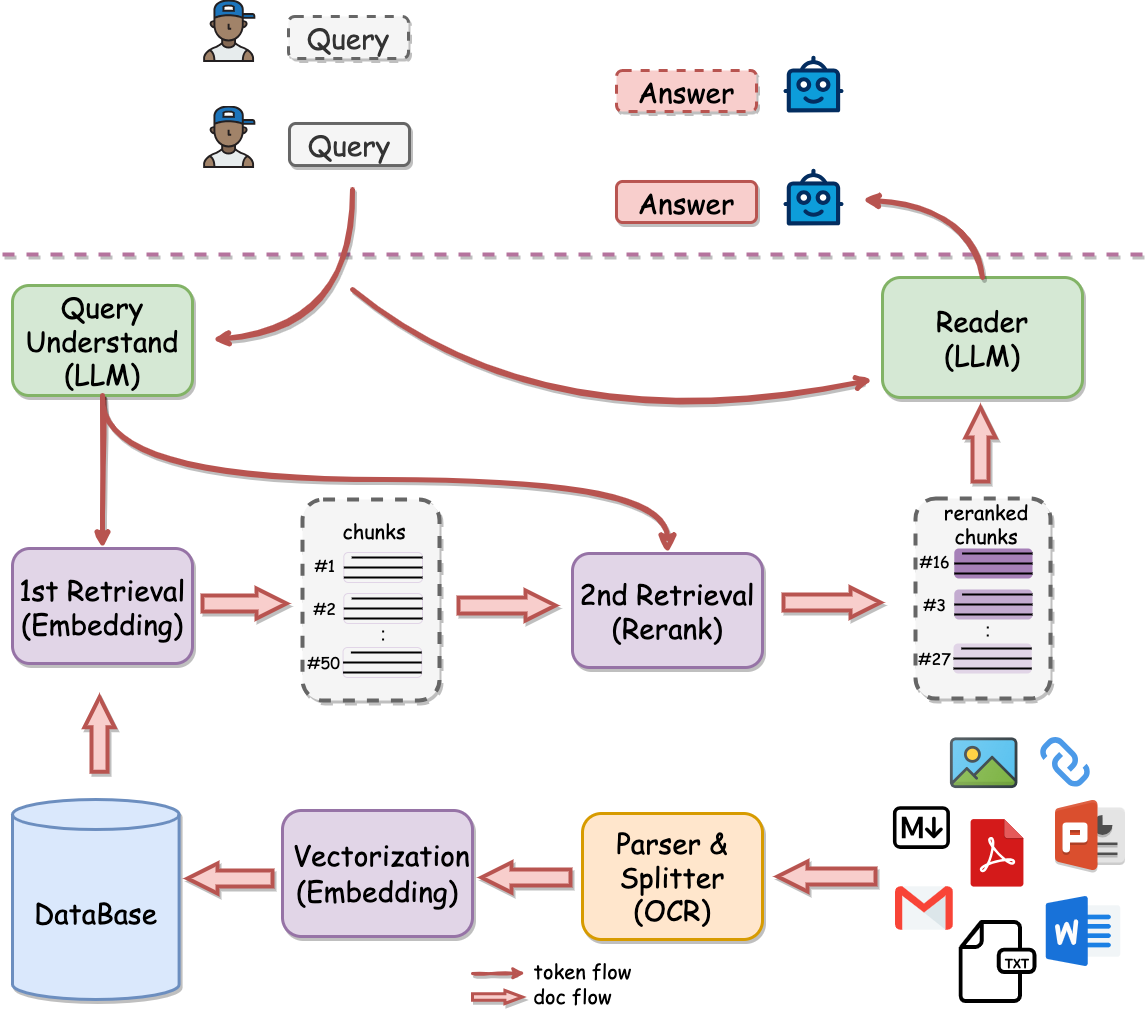
The process of PDF parsing is carried out in the split_file_to_docs() function.
@get_time
def split_file_to_docs(self):
...
...
elif self.file_path.lower().endswith(".pdf"):
markdown_file = get_pdf_result_sync(self.file_path)
if markdown_file:
docs = convert_markdown_to_langchaindoc(markdown_file)
docs = self.markdown_process(docs)
images_dir = os.path.join(IMAGES_ROOT_PATH, self.file_id)
self.copy_images(os.path.dirname(markdown_file), images_dir)
else:
insert_logger.warning(
f'Error in Powerful PDF parsing, use fast PDF parser instead.')
loader = UnstructuredPaddlePDFLoader(self.file_path, strategy="fast")
docs = loader.load()PDF Parser Server
The above code initially uses the get_pdf_result_sync function to convert PDFs into Markdown format text. It utilizes a custom-built PDF parser server.
def get_pdf_result_sync(file_path):
try:
data = {
'filename': file_path,
'save_dir': os.path.dirname(file_path)
}
headers = {"content-type": "application/json"}
response = requests.post(f"http://{LOCAL_PDF_PARSER_SERVICE_URL}/pdfparser", json=data, headers=headers,
timeout=240)
response.raise_for_status()
response_json = response.json()
markdown_file = response_json.get('markdown_file')
return markdown_file
except Exception as e:
insert_logger.warning(f"pdf parser error: {traceback.format_exc()}")
return NoneThe code for the PDF Parser Server is as follows.
@app.post("/pdfparser")
async def pdf_parser(request: Request):
filename = safe_get(request, 'filename')
save_dir = safe_get(request, 'save_dir')
pdf_parser_: PdfLoader = request.app.ctx.pdf_parser
markdown_file = pdf_parser_.load_to_markdown(filename, save_dir)
return json({"markdown_file": markdown_file})
if __name__ == '__main__':
app.run(host="0.0.0.0", port=9009, workers=args.workers)The primary functionality is implemented in the pdf_parser_.load_to_markdown function, and its main workflow is illustrated in Figure 3.

Two Branches
Subsequently, the process of PDF parsing mainly involves two branches:
If the Markdown format file (
markdown_file) is successfully obtained, the code then proceeds to process this Markdown.If there are issues during the conversion from PDF to Markdown (i.e., if
markdown_fileis empty), the code uses class UnstructuredPaddlePDFLoader to handle the PDF files.
The UnstructuredPaddlePDFLoader operates in 'fast' mode, utilizing the PyMuPDF and unstructured frameworks, but it does not perform OCR. This approach offers faster but potentially less accurate PDF parsing.
class UnstructuredPaddlePDFLoader(UnstructuredFileLoader):
"""Loader that uses unstructured to load image files, such as PNGs and JPGs."""
def __init__(
self,
file_path: Union[str, List[str]],
mode: str = "single",
**unstructured_kwargs: Any,
):
"""Initialize with file path."""
super().__init__(file_path=file_path, mode=mode, **unstructured_kwargs)
def _get_elements(self) -> List:
def pdf_ocr_txt(filepath, dir_path="tmp_files"):
full_dir_path = os.path.join(os.path.dirname(filepath), dir_path)
if not os.path.exists(full_dir_path):
os.makedirs(full_dir_path)
# call PymuPDF
doc = fitz.open(filepath)
txt_file_path = os.path.join(full_dir_path, "{}.txt".format(os.path.split(filepath)[-1]))
img_name = os.path.join(full_dir_path, 'tmp.png')
with open(txt_file_path, 'w', encoding='utf-8') as fout:
for i in tqdm(range(doc.page_count)):
page = doc.load_page(i)
# pix = page.get_pixmap(dpi=300)
# img = np.frombuffer(pix.samples, dtype=np.uint8).reshape((pix.h, pix.w, pix.n))
#
# img_data = {"img64": base64.b64encode(img).decode("utf-8"), "height": pix.h, "width": pix.w,
# "channels": pix.n}
# result = self.ocr_engine(img_data)
# result = [line for line in result if line]
# ocr_result = [i[1][0] for line in result for i in line]
result = page.get_text()
fout.write(result + '\n\n')
if os.path.exists(img_name):
os.remove(img_name)
return txt_file_path
txt_file_path = pdf_ocr_txt(self.file_path)
# call unstructured's partition_text function
return partition_text(filename=txt_file_path, **self.unstructured_kwargs)RAGFlow
RAGFlow is an RAG engine that leverages deep document understanding. It provides a streamlined workflow for businesses of all sizes, combining LLMs to offer reliable question-answering capabilities. These capabilities are supported by robust citations from a variety of complexly formatted data sources.
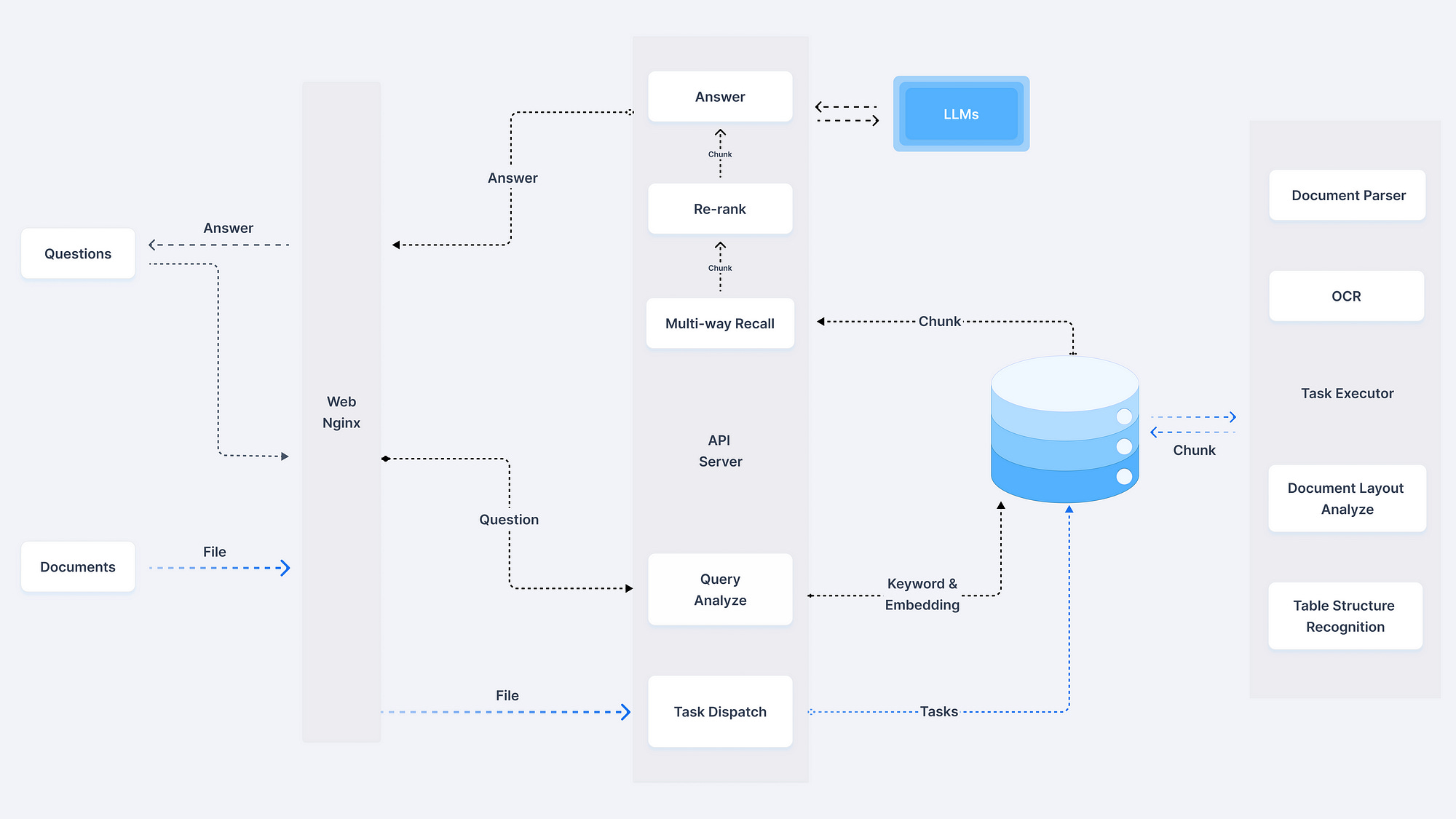
From the right side of Figure 4, it is evident that RAGFlow employs a variety of parsing techniques, including OCR, document layout analysis, and table recognition, among others. This illustration also highlights RAGFlow’s core capability in document parsing.
The PDF parsing functionality of RAGFlow is primarily implemented in the class RAGFlowPdfParser. This class implements a __call__() method, and its main workflow is illustrated in Figure 5.

As shown in Figure 5, it fundamentally adheres to the pipeline-based methods process we previously described.
Here, we focus on the approach of layout analysis. It can primarily identify the following eleven types of page elements.
class LayoutRecognizer(Recognizer):
labels = [
"_background_",
"Text",
"Title",
"Figure",
"Figure caption",
"Table",
"Table caption",
"Header",
"Footer",
"Reference",
"Equation",
]
def __init__(self, domain):
try:
model_dir = os.path.join(
get_project_base_directory(),
"rag/res/deepdoc")
super().__init__(self.labels, domain, model_dir)
except Exception as e:
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc",
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
local_dir_use_symlinks=False)
super().__init__(self.labels, domain, model_dir)
self.garbage_layouts = ["footer", "header", "reference"]
...
...Upon initialization, this class attempts to load the model from a predefined file directory. If loading fails, it automatically downloads the required model from Hugging Face Hub. The layout analysis model should be custom-trained by the developers.
After the model is loaded, the primary __call__ process is illustrated in Figure 6.
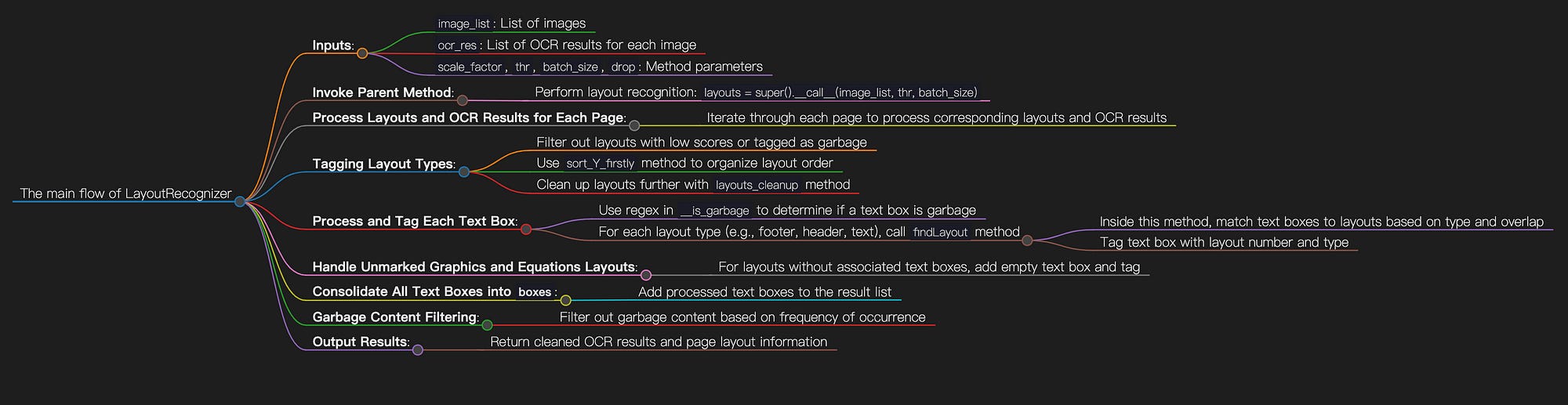
By meticulously combining OCR results with layout recognition, __call__ function achieves in-depth analysis and precise tagging of text and layouts in document images, enhancing the accuracy and efficiency of document content processing. It also includes a layout cleaning and garbage filtering mechanism, accurately removing irrelevant text through regular expressions and custom logic.
Cognita
Cognita is a RAG framework designed for building modular, open-source applications for production. Its architecture is illustrated in Figure 7.
Keep reading with a 7-day free trial
Subscribe to AI Exploration Journey to keep reading this post and get 7 days of free access to the full post archives.