


AI Innovations and Trends 02: VisRAG, GraphRAG, RAGLAB, and More

This article is the second in this series. Today we will look at five advancements in AI, which are:
VisRAG: Farewell to Document Parsing
Graph RAG: A Survey
RAGLAB: A Modular and Research-Oriented Unified Framework for RAG
rerankers: A Lightweight Python Library to Unify Ranking Methods
Quantized Llama 3.2 Models (1B and 3B)
VisRAG: Farewell to Document Parsing
Open source code: https://github.com/openbmb/visrag
As shown in Figure 1, traditional text-based RAG (TextRAG) relies on parsed texts for retrieval and generation, losing visual information in multimodal documents. In contrast, Vision-based RAG (VisRAG) uses a VLM-based retriever and generator to directly process the document page's image. This approach preserves all information from the original page.

Retrieval Stage
Task: To retrieve relevant pages from a corpus based on a user query, enabling accurate information augmentation for generation.
Method:
Dual-Encoder Paradigm: Uses a VLM rather than an LLM to map the query and document page images into the same embedding space for similarity calculation.
Vision-Language Model (VLM): Encodes document pages as images directly, preserving visual and textual information without text parsing.
Similarity Scoring: Computes cosine similarity between the query and page embeddings to select the most relevant pages.
Generation Stage
Task: To generate an accurate and contextually enriched response based on the user query and retrieved pages.
Method:
Single-Image and Multi-Image Handling:
For VLMs accepting single images, VisRAG applies page concatenation or weighted selection methods to combine information from multiple retrieved pages.
For VLMs supporting multi-image input, VisRAG leverages these models directly to process all retrieved pages together.
Weighted Selection: Calculates the answer confidence across multiple pages, selecting the response with the highest weighted probability.
Insights
VisRAG is a multi-modal RAG approach that eliminates the document parsing stage, thereby preserving comprehensive information for retrieval and generation.
While VisRAG demonstrates many advantages, it also presents challenges, particularly regarding computational resource requirements. Directly processing images requires powerful VLMs and significant computational support. Additionally, the approach’s dependency on model and data scale may require further adjustments for wider adoption in other domains.
Graph RAG: A Survey
This survey provides a systematic introduction to Graph RAG and its key components.
While RAG improves on LLMs by retrieving relevant text, it still falls short in capturing deep relational knowledge, leading to incomplete answers.
As shown in Figure 2, GraphRAG addresses this issue by leveraging the structural information inherent in graphs, enabling more precise and contextually aware responses.
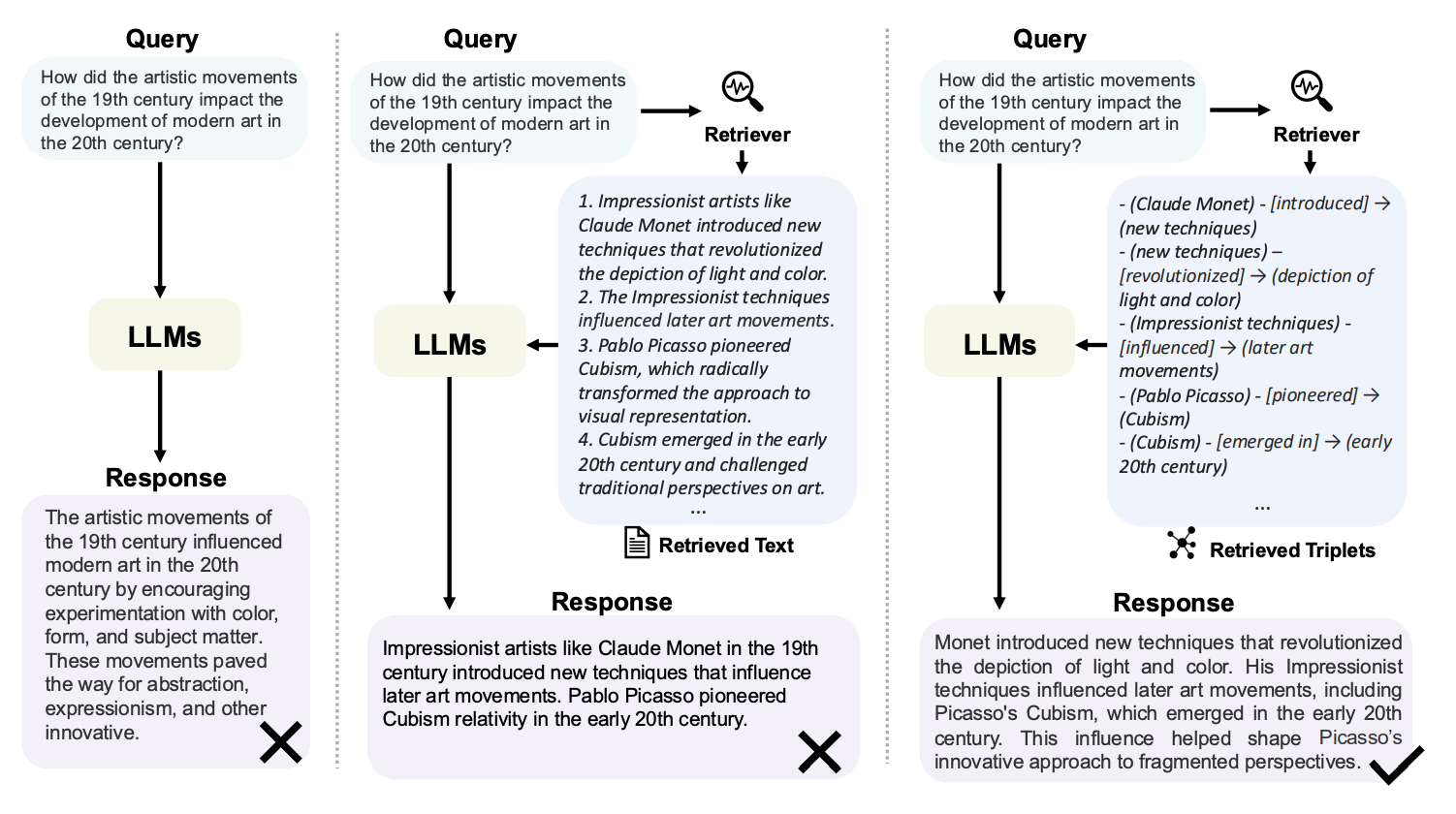
GraphRAG is a novel approach that combines the strengths of RAG with the robustness of graph-based data structures. By retrieving graph elements such as nodes, triples, paths, and subgraphs, GraphRAG enriches LLM outputs with relational knowledge, ensuring more accurate and comprehensive answers.
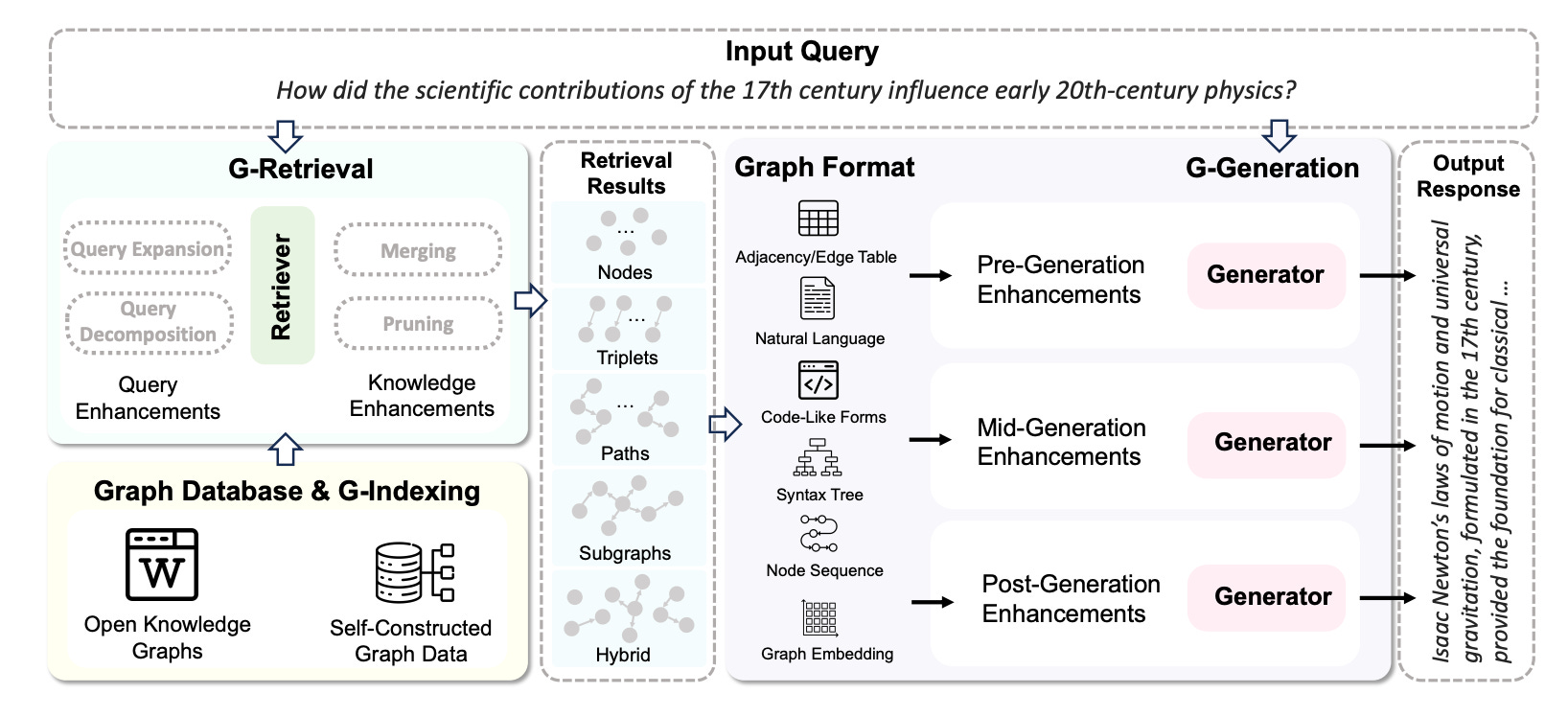
The workflow of GraphRAG, as depicted in Figure 3, is divided into three key stages:
Graph-Based Indexing (G-Indexing): This stage involves constructing or selecting a graph database relevant to the downstream tasks, indexing it for efficient retrieval.
Graph-Guided Retrieval (G-Retrieval): Here, the system retrieves the most pertinent graph elements based on a given query.
Graph-Enhanced Generation (G-Generation): Finally, the retrieved graph data is used to generate responses that are both accurate and contextually rich.
RAGLAB: A Modular and Research-Oriented Unified Framework for RAG
Open source code: https://github.com/fate-ubw/RAGLab
Two key issues have hindered the development of RAG. First, there's a growing lack of comprehensive and fair comparisons among novel RAG algorithms. Second, open-source tools like LlamaIndex and LangChain use high-level abstractions, resulting in reduced transparency and limiting the ability to develop new algorithms and evaluation metrics.
RAGLAB is a modular, research-oriented open-source library designed to close this gap.
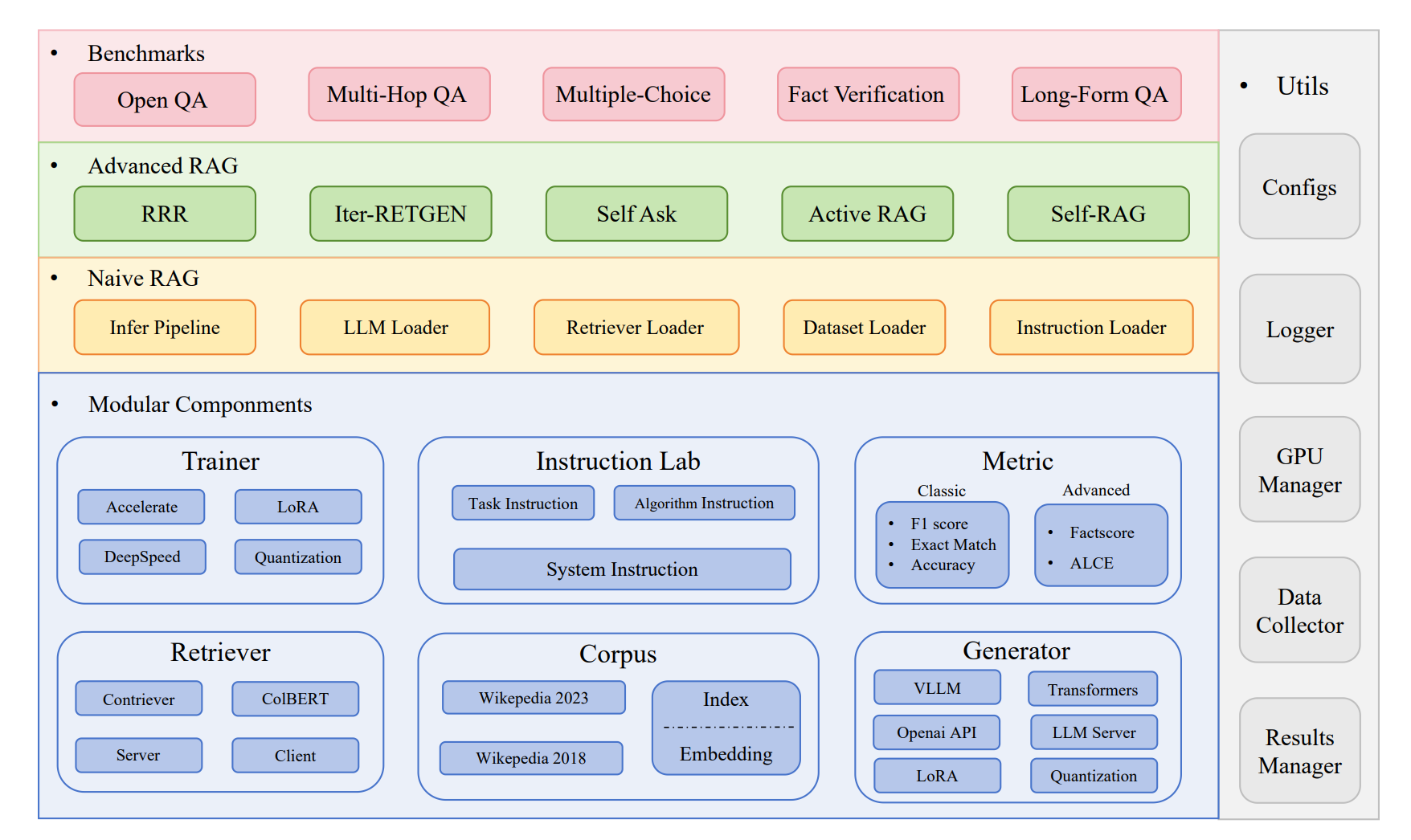
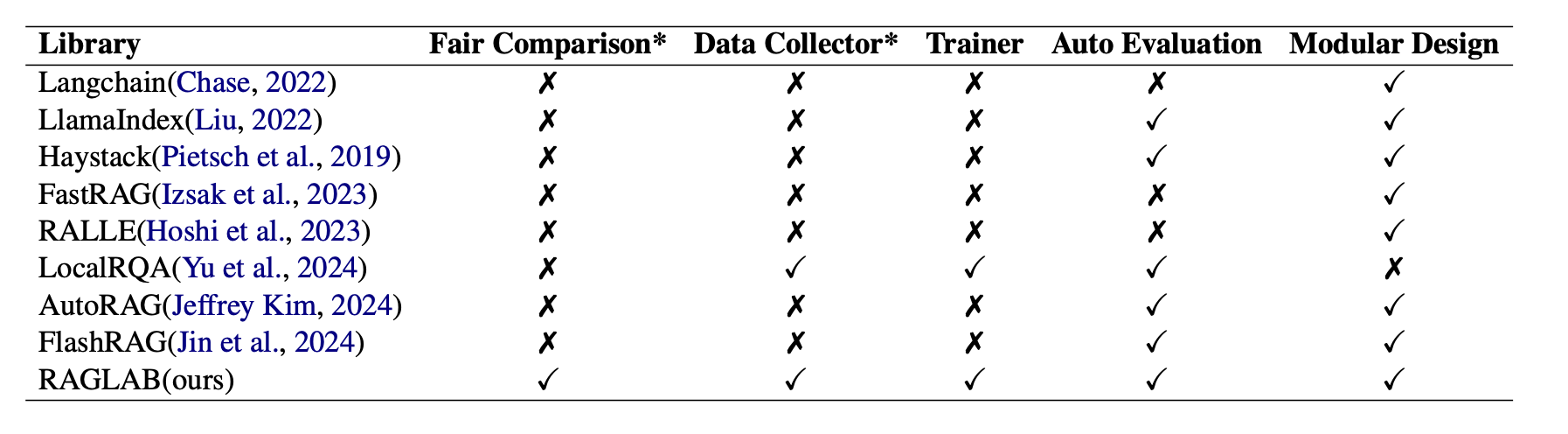
Figure 5 is a comparison between RAGLAB and some existing RAG frameworks
Insights
RAGLAB has some limitations:
Limited Number of Algorithms and Datasets
Lack of Diversity in Knowledge Bases
Lack of a User-Friendly Graphical Interface
These limitations can be gradually addressed in future versions by expanding algorithms, increasing datasets, and optimizing resource efficiency to meet broader research and application needs.
rerankers: A Lightweight Python Library to Unify Ranking Methods
Open source code: https://github.com/answerdotai/rerankers
We know that reranking is a crucial component in information retrieval and RAG, typically employed after the initial retrieval of candidate documents. It uses stronger models—often neural networks—to reorder these documents, thereby enhancing retrieval quality.
The rerankers library is a lightweight Python tool that unifies various reranking methods. It offers a standardized interface for loading and using different reranking techniques, allowing users to switch between methods by changing just one line of Python code.
from rerankers import Reranker
# Cross-encoder default. You can specify a 'lang' parameter to load a multilingual version!
ranker = Reranker('cross-encoder')
# Specific cross-encoder
ranker = Reranker('mixedbread-ai/mxbai-rerank-large-v1', model_type='cross-encoder')
# FlashRank default. You can specify a 'lang' parameter to load a multilingual version!
ranker = Reranker('flashrank')
# Specific flashrank model.
ranker = Reranker('ce-esci-MiniLM-L12-v2', model_type='flashrank')
# Default T5 Seq2Seq reranker
ranker = Reranker("t5")
# Specific T5 Seq2Seq reranker
ranker = Reranker("unicamp-dl/InRanker-base", model_type = "t5")
# API (Cohere)
ranker = Reranker("cohere", lang='en' (or 'other'), api_key = API_KEY)
# Custom Cohere model? No problem!
ranker = Reranker("my_model_name", api_provider = "cohere", api_key = API_KEY)
...
...Quantized Llama 3.2 Models (1B and 3B)
Meta AI released its first lightweight quantized Llama models that are small and performant enough to run on many popular mobile devices.
They primarily used two techniques for quantizing Llama 3.2 1B and 3B models: Quantization-Aware Training with LoRA adaptors, which prioritizes accuracy, and SpinQuant, a state-of-the-art post-training quantization method that prioritizes portability.
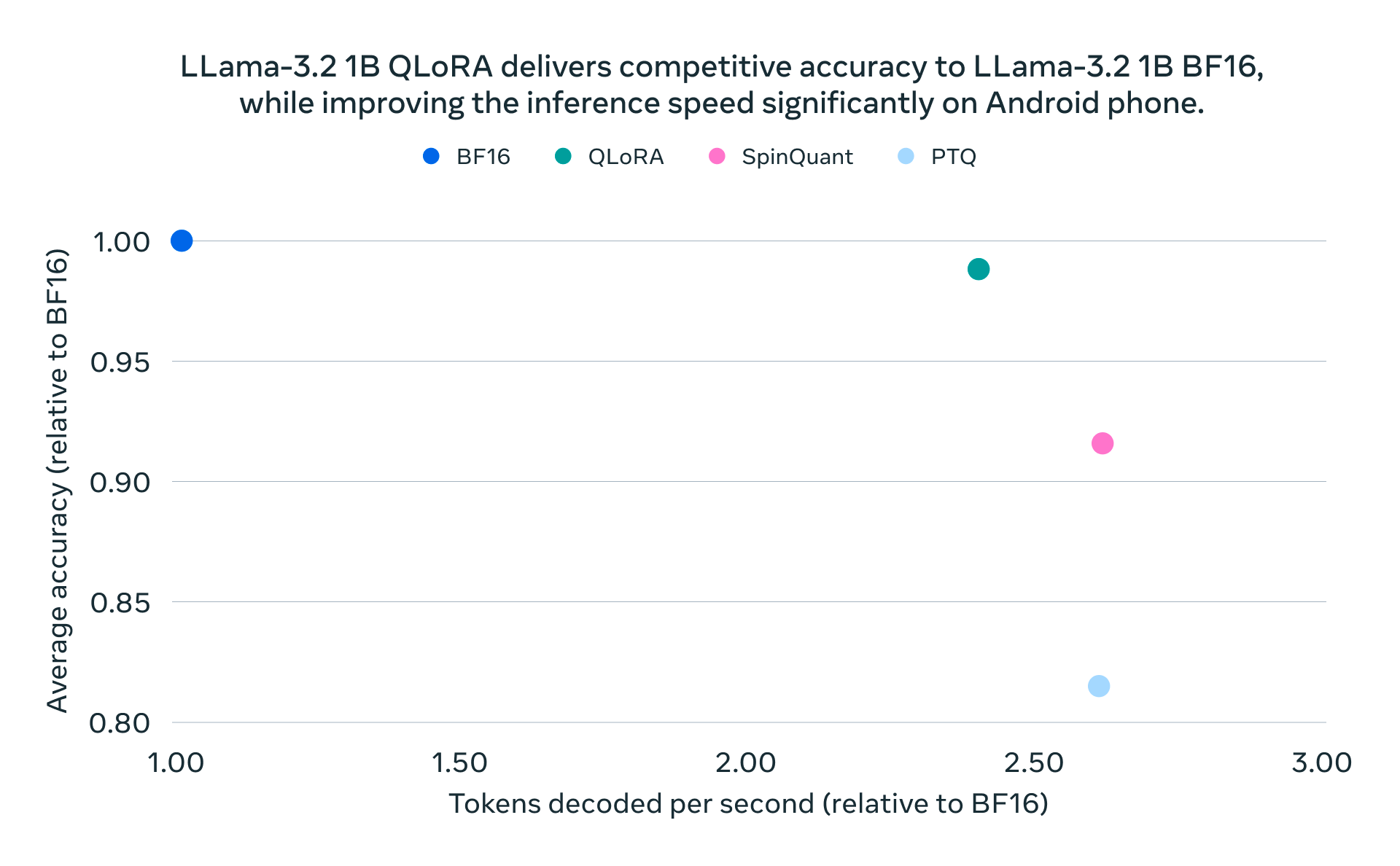
As the first quantized models in this Llama category, these instruction-tuned models maintain the same quality and safety standards as the original 1B and 3B models while achieving a 2-4x speedup. Additionally, compared to the original BF16 format, they achieve an average 56% reduction in model size and a 41% reduction in memory usage.
Finally, if you’re interested in the series, feel free to check out my other articles.