


AI Innovations and Insights 33: PIKE-RAG and DeepRAG

Welcome to the 33rd installment of this thought-provoking series. In today’s article, we’ll explore two captivating topics:
PIKE-RAG: From DIY Furniture to Interior Design
Fast Delivery, Smarter Routing: DeepRAG Makes LLMs Knowledge Couriers
PIKE-RAG: From DIY Furniture to Interior Design
Open-source code: https://github.com/microsoft/PIKE-RAG
Traditional RAG is like buying a DIY furniture kit—you get all the parts and instructions, but you have to put everything together yourself.
PIKE-RAG, on the other hand, is like hiring an interior designer. It first understands your style and needs, selects the best pieces for you, and arranges them perfectly, making your space both beautiful and functional.
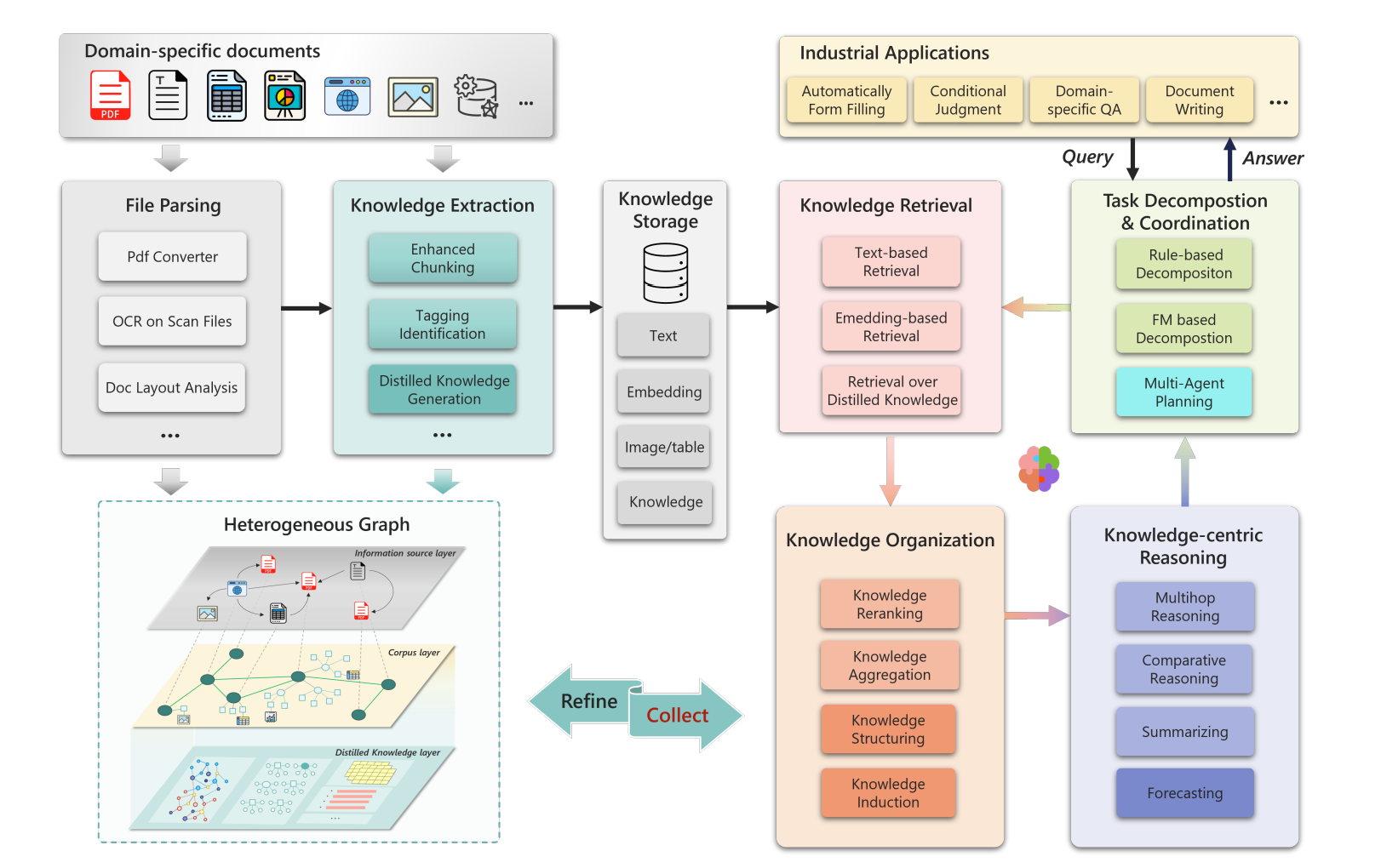
As shown in Figure 1, PIKE-RAG consists of several key components: file parsing, knowledge extraction, knowledge storage, knowledge retrieval, knowledge organization, task decomposition and coordination, and knowledge-centric reasoning. Each component can be customized to adapt to the system’s evolving needs.
Insights
PIKE-RAG a well-researched and detailed piece of work, and it's also open-source.
Here are a few points that caught my interest.
The first point is File Parsing (AI Exploration Journey: PDF Parsing and Document Intelligence). Since documents often contain complex tables, charts, and graphics, the first step should use layout analysis (Demystifying PDF Parsing 02: Pipeline-Based Method) to preserve these multimodal elements. Charts and graphics can then be processed using vision-language models (VLMs) to generate descriptions that support knowledge retrieval.
This approach offers two key advantages. First, the extracted layout information helps with text chunking, ensuring that the divided text remains contextually complete. Second, compared to an end-to-end method (Demystifying PDF Parsing 03: OCR-Free Small Model-Based Method, Demystifying PDF Parsing 04: OCR-Free Large Multimodal Model-Based Method), this divide-and-conquer strategy allows for greater customization while leveraging the benefits of a pipeline-based approach (Demystifying PDF Parsing 02: Pipeline-Based Method).
The second point is structuring the knowledge base as a multi-layer heterogeneous graph, as shown in Figure 2, it consists of several layers:
Information resource layer : In this layer, the diverse information sources are treated as nodes, with connections that illustrate how they reference each other.
Corpus layer: This layer organizes the parsed information into sections and chunks while preserving the document’s original hierarchical structure. Multi-modal content such as tables and figures is summarized by LLMs and integrated as chunk nodes. This layer enables knowledge extraction with varying levels of granularity.
Distilled knowledge layer: This process uses techniques such as Named Entity Recognition and relationship extraction to get key entities and their logical connections. By clearly capturing these relationships, it supports advanced reasoning processes.

In this architecture, nodes can represent various elements—documents, chapters, text chunks, charts, tables, and refined knowledge—while edges define relationships between them.
The last point is that PIKE-RAG divides questions into four types:
Factual questions: Extracting clear and objective facts directly from existing knowledge.
Linkable reasoning questions: Requiring reasoning and linking across multiple pieces of knowledge to derive the correct answer.
Predictive questions: Identifying patterns and making inferences based on existing data to predict future outcomes.
Creative questions: Combining knowledge and logic to generate new insights or innovative solutions.

To measure how well a system can handle these types of questions, PIKE-RAG defines four levels (L1, L2, L3, and L4), creating a roadmap for gradually enhancing RAG capabilities.
As shown in Figure 3, different levels of RAG are handled in different ways.
Fast Delivery, Smarter Routing: DeepRAG Makes LLMs Knowledge Couriers
Vivid Description
DeepRAG is like a smart delivery rider who doesn’t just rush to deliver all the orders at once without thinking. Instead, he plans the best route (task decomposition) based on the delivery locations. If he knows the way by heart (LLM's internal knowledge), he heads straight there. But if he hits an unfamiliar street (missing knowledge), he checks the map (external retrieval) to find the best path.
Overview
Traditional RAG struggles with ineffective task decomposition and redundant retrieval.
As shown on the right side of Figure 4, DeepRAG's retrieval narrative ensures a structured and adaptive retrieval process. It generates subqueries based on previously retrieved information, while atomic decisions dynamically determine whether to fetch external knowledge for each subquery or rely solely on parameterized knowledge.

DeepRAG is built by training an LLM to enhance retrieval-based reasoning. As shown in Figure 5, the training process of DeepRAG follows three key steps: (1) Binary Tree Search, (2) Imitation Learning, and (3) Chain of Calibration.

Given a dataset, the process starts with binary tree search to generate data for imitation learning, helping the model learn retrieval patterns. Then, binary tree search is used again to create preference data, refining the LLM's understanding of its knowledge boundaries.
Commentary
Here are two great takeaways from this study, I thought they were worth sharing.
The first is a classification of adaptive RAG methods, which can be divided into three categories.
Classifier-based methods: rely on training an additional classifier to make retrieval decisions. A well-known example is Adaptive-RAG, which we’ve covered before (Advanced RAG 11: Query Classification and Refinement). It trains a query complexity classifier, which is a smaller language model.
Confidence-based methods: rely on threshold-dependent uncertainty metrics. A key example is FLARE.
LLM-based methods: generate retrieval decisions but often struggle to recognize their own knowledge boundaries, making it unreliable to let the model decide when to retrieve. A well-known example is Self-RAG, which we’ve also covered before (Advanced RAG 08: Self-RAG).
It's worth mentioning that SEAKR, which we introduced earlier (Unleashing AI's Self-Awareness: How SEAKR Revolutionizes Knowledge Retrieval in LLMs), uses the internal state of an LLM to determine when it needs external knowledge support (i.e., retrieving external information). SEAKR adopts a more fine-grained manner, making it an adaptive RAG method rather than merely a LLM-based method.
The second aspect is enhancing reasoning ability within RAG. Here are some representative approaches:
Self-RAG (Advanced RAG 08: Self-RAG) and Auto-RAG improve reasoning in RAG frameworks through automatic data synthesis.
Search-o1 incorporates retrieval into the reasoning process, creating an agentic system, though its applicability is limited to reasoning LLMs like OpenAI o1.
AirRAG combines Monte Carlo Tree Search (MCTS) and self-consistency to enhance retrieval-based reasoning.
Unlike these methods, which rely heavily on extensive retrieval operations or reasoning LLMs, DeepRAG offers an end-to-end approach that enables any model to perform step-by-step retrieval-based reasoning as needed.
Finally, if you’re interested in the series, feel free to check out my other articles.