


AI Innovations and Insights 18: GARLIC
A Smart Librarian for Hierarchical Graph-Based RAG

This article is the 18th in this promising series.
From a personal interest standpoint, I've always been fascinated by data structures, as you can see in my previous articles. That's why I pay close attention to any RAG systems that incorporate advanced data structures.
Today, we’ll be discussing GARLIC, which perfectly embodies this characteristic.
The video contains a mind map:
Vivid Description
Imagine you're in a library, trying to find the most important information in a 1000-page book—like each character’s journey and key plot points. Traditional methods can feel like working with two clumsy assistants:
Assistant A (traditional RAG) cuts the book into page-by-page fragments, and hands you random pages based on keywords. But, he can't explain how these pages fit together or their context.
Assistant B (tree-based RAG) turns the book into a tree, searching one branch at a time. If you need something from another branch, he has to climb back to the top and start over, wasting time.
Now, imagine an "intelligent librarian" like GARLIC:
He creates a hierarchical map of the book, highlighting key events and relationships, so you can see how everything connects.
When you ask a question, like “What did the protagonist go through?” he quickly navigates the most relevant paths and gives you a clear, concise answer.
He knows when to stop, so you're not stuck searching endlessly.
This method helps GARLIC give you more accurate, comprehensive answers in less time.
Now, let's dive into the detailed introduction.
Background
In the domain of long document question answering (QA), Retrieval-Augmented Generation (RAG) methods have been dominant. These methods split long texts into smaller chunks and retrieve relevant pieces to input into LLMs.
However, RAG comes with critical limitation:
Global Context Loss: Chunks often lose the overall context, which is essential for complex queries that require connections across multiple events.
Dense embedding: Traditional RAG methods rely on dense embeddings to compute node relevance, but this approach has room for improvement.
Inefficiency in Retrieval: Tree-based RAG methods like RAPTOR and MeMWalker struggle with rigid single-path traversal, limiting their flexibility.
Computational Overheads: Directly feeding long texts into advanced LLMs (e.g., Llama 3.1) is computationally expensive, particularly for inputs exceeding 100K tokens.

For example, imagine you are searching for the key events in a 1,000-page novel. Traditional RAG methods only give you isolated paragraphs, RAPTOR limits your search to one fixed storyline, while feeding the whole novel into an LLM would burn significant GPU resources.
What if we could dynamically find the most critical information, flexibly navigating the content like a smart librarian? This is the key idea behind GARLIC.
GARLIC
As shown in Figure 2, GARLIC introduces LLM-Guided Dynamic Progress Control using a Hierarchical Weighted Directed Acyclic Graph (HWDAG), a graph-based retrieval approach.
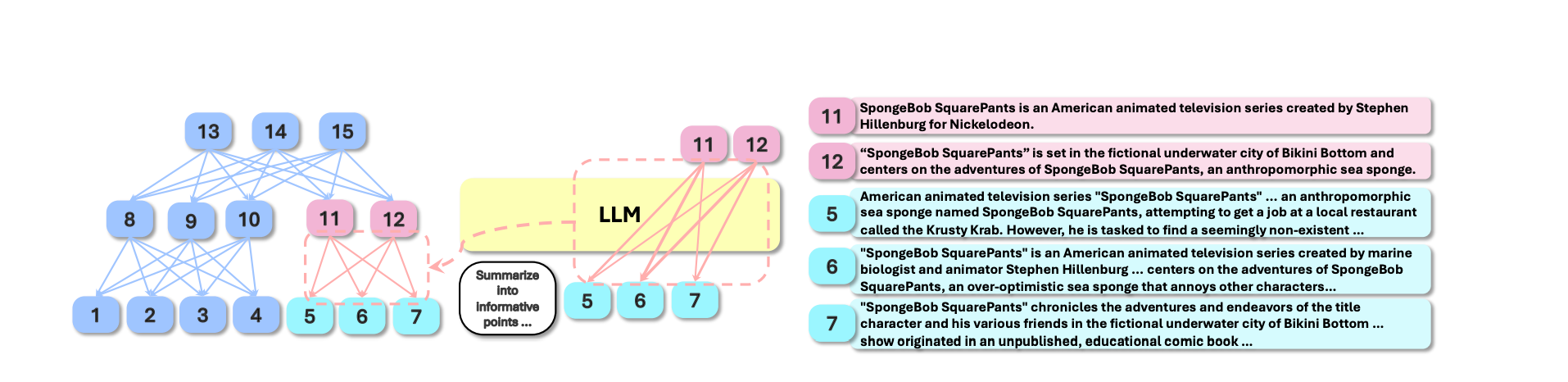
The key innovations of GARLIC:
Building a graph where each node represents an Information Point (IP), summarizing granular events.
Using attention weights from LLMs for node traversal instead of dense embeddings.
Dynamically controlling the retrieval process to stop when enough information is collected.
This method ensures that queries requiring detailed or global context can be efficiently handled without unnecessary computation.
Key Steps
GARLIC operates in two main stages:
Summary Graph Construction:
The input document is split into chunks (300 tokens). An LLM summarizes these chunks into bullet-point Information Points (IPs).
As shown in Figure 2, summarization continues recursively, forming a multi-level HWDAG, where:
Nodes represent IPs summarizing events.
Edges are weighted using LLM attention scores, capturing relationships between IPs.
Each node focuses on a single event, enabling fine-grained retrieval.
Example: Imagine a book is summarized as a hierarchical graph. Each bullet-point summary (IP) is a node, while edges represent how strongly one summary connects to another event.
Dynamic Graph Search:
Nodes are retrieved via Greedy Best-First Search (GBFS) and fed to the LLM.
The LLM checks if enough nodes are present to answer the query, enabled by KV caching at no extra cost. Once sufficient nodes are collected, the final answer is generated.
It uses LLM attention weights during traversal instead of dense embeddings, improving accuracy.

Commentary
From the algorithm of GARLIC, I have the following insights:
Graph-structured retrieval may be the key direction for processing long documents.
Retrieval based on attention weights rather than embedding similarity may be explored in broader scenarios.
While GARLIC is innovative, but in my view, there are still challenges:
Attention score normalization uses empirical methods that may be inconsistent across different contexts.
The dynamic search stop mechanism relies on LLM judgment of "sufficient information," but this varies by query complexity and may cause early or late stopping in complex tasks.
While HWDAG's multi-path retrieval provides comprehensive coverage, path overlap can waste computational resources without clear redundancy handling.
Graph construction requires intensive preprocessing through layer-by-layer summarization, creating high computational costs for large documents. In addition, it appears to lack incremental update capabilities when documents change.
Finally, if you’re interested in the series, feel free to check out my other articles.