

AI Innovations and Insights 11: PDF-WuKong and PersonaRAG
You can watch the video:
This article is the 11th in this exciting series.
In the previous ten articles, I explored the structure and content of this series. I think the articles should maintain the content of AI innovations with brief commentary or insights.
Therefore, "AI Innovations and Trends" doesn't quite fit this series, so from this article onwards, the series will be renamed to "AI Innovations and Insights".
Today, we will delve into two promising topics in AI:
PDF-WuKong: Understanding Long PDF Documents Efficiently
PersonaRAG: Customizing with User-Centric Agents
PDF-WuKong: Understanding Long PDF Documents Efficiently

Current large language models (LLMs) face the following challenges when processing long documents:
Single Modality Limitations: Traditional methods either handle plain text only (ignoring visual elements like charts and figures) or treat each page as a separate image. Both approaches fail to effectively comprehend interleaved text and image content.
Efficiency and Accuracy Issues with Long Documents: The performance of existing methods significantly deteriorates as document length increases, particularly when dealing with multi-page documents containing substantial redundant information.
Lack of Fine-Grained Understanding of Multimodal Content: Users’ queries are often only related to a small number of text blocks or diagrams in a long document.
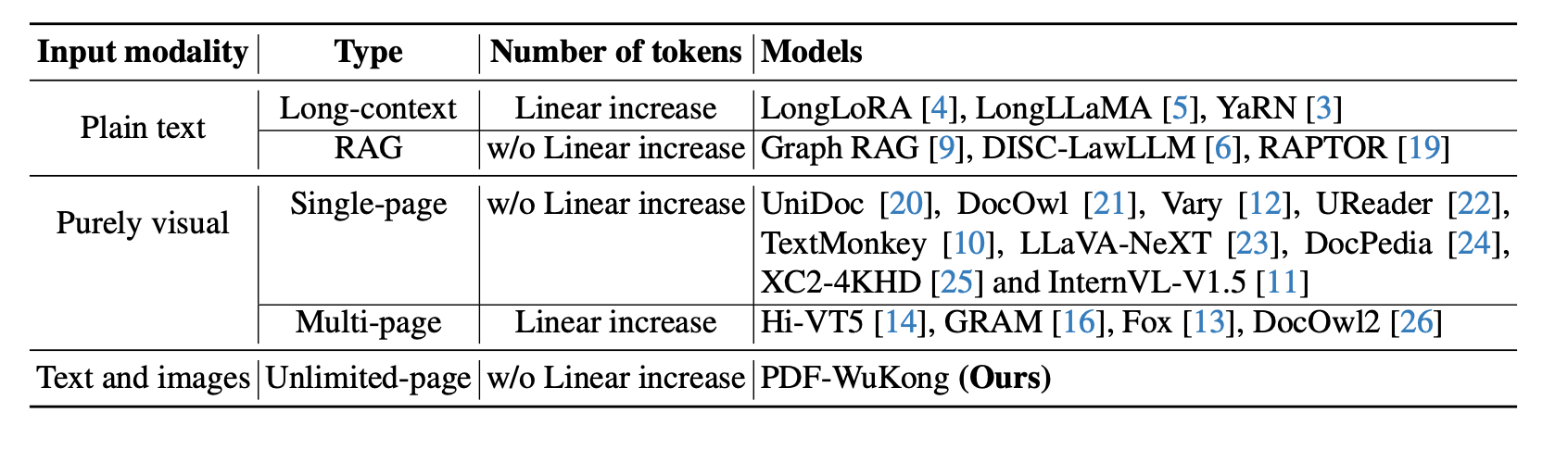
Figure 2 is a comparison of current research for understanding multi-page long documents.
PDF-WuKong integrates an end-to-end sparse sampling mechanism with a multimodal large language model (MLLM). The sparse sampler identifies and extracts the most relevant text and image content based on user queries, reducing redundant information and computational overhead.
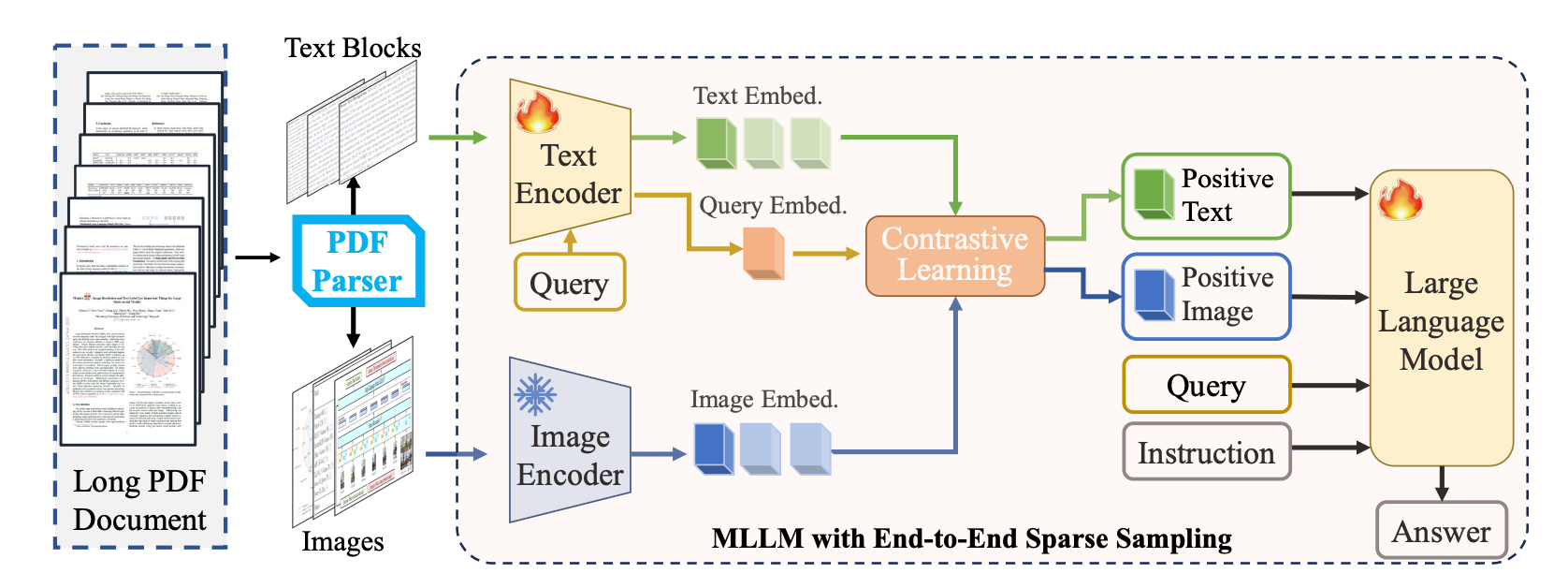
As shown in Figure 3, PDF-WuKong consists of three parts: a document parser, a sparse sampler, and an LLM.
The document parsing stage converts the input PDF document into machine-readable content with interleaved text and images. The sparse sampler then encodes the text blocks and images separately and caches their embeddings. When a user inputs a query, the most relevant content is sampled using a simple similarity measure. Finally, the query and sampled tokens are input into the LLM to generate the answer.
The detailed algorithms for both inference and training are illustrated in Figure 4.

Commentary
In my view, PDF-WuKong has some differences from RAG. For example, traditional RAG typically contains a retriever (like Dense Retriever) and a generation model (like Llama3) that operate independently. In contrast, PDF-WuKong's sparse sampler is directly integrated with the multimodal LLM, forming an end-to-end unified architecture.
In addition, sparse sampler illustrates that the power of LLMs doesn’t rely on processing massive amounts of input but on precise selection and dynamic optimization. However, the current sampling relies on similarity scoring, which might fail with ambiguous or multi-faceted queries.
PersonaRAG: Customizing with User-Centric Agents
Open-Source code: https://github.com/padas-lab-de/PersonaRAG
Traditional RAG systems lack personalization capabilities for user-specific needs. PersonaRAG uses user-centric agents to dynamically personalize information retrieval, improving output quality.
I have detailed this method, and now I have some new insights.

As shown in Figure 5, vanilla RAG and Chain-of-Thought use passive learning, while PersonaRAG involves user-centric knowledge acquisition.

As shown in Figure 6, PersonaRAG is an innovative framework that integrates multiple specialized agents to dynamically optimize and personalize information retrieval. It follows a three-step process:
Retrieval: Documents are retrieved based on the user's query using a combination of traditional search indices and dynamic, context-aware systems.
User Interaction Analysis: PersonaRAG employs several agents to analyze user interactions in real-time, including:
User Profile Agent: Maintains and updates user profile data based on historical interactions and preferences.
Contextual Retrieval Agent: Adjusts search queries and prioritizes results based on user profiles.
Live Session Agent: Monitors real-time user actions to dynamically adjust the ongoing session.
Document Ranking Agent: Ranks documents by integrating insights from other agents.
Feedback Agent: Collects implicit and explicit user feedback to continuously optimize the system.
Cognitive Dynamic Adaptation: Using adaptive learning principles, it employs real-time user data to continuously improve retrieval processes. The system adjusts query responses based on initial user needs and refines them with incoming data, enabling personalized results and real-time error correction.

Figure 8 is a randomly selected case, demonstrating the effectiveness of PersonaRAG.

Commentary
PersonaRAG shows advancements in RAG systems by integrating user-centric agents to dynamically personalize and adjust information retrieval processes.
From my perspective, the multi-agent framework, while powerful, also increases system complexity and computational demands through agent interactions and real-time data processing. Large-scale industrial deployment would require optimized agent coordination and distributed computing to manage resources effectively.
In addition, given the system’s reliance on collecting and analyzing substantial amounts of user interaction data, privacy concerns and regulatory compliance (e.g., GDPR) are challenges.
Finally, if you’re interested in the series, feel free to check out my other articles.