
Advanced RAG 11: Query Classification and Refinement
Priciples, Code Explanation and Insights about Adaptive-RAG and RQ-RAG

While traditional RAG technology can mitigate the inaccuracies of LLM’s answers, it does not enhance the initial query in any way. This is illustrated in the red box in Figure 1.
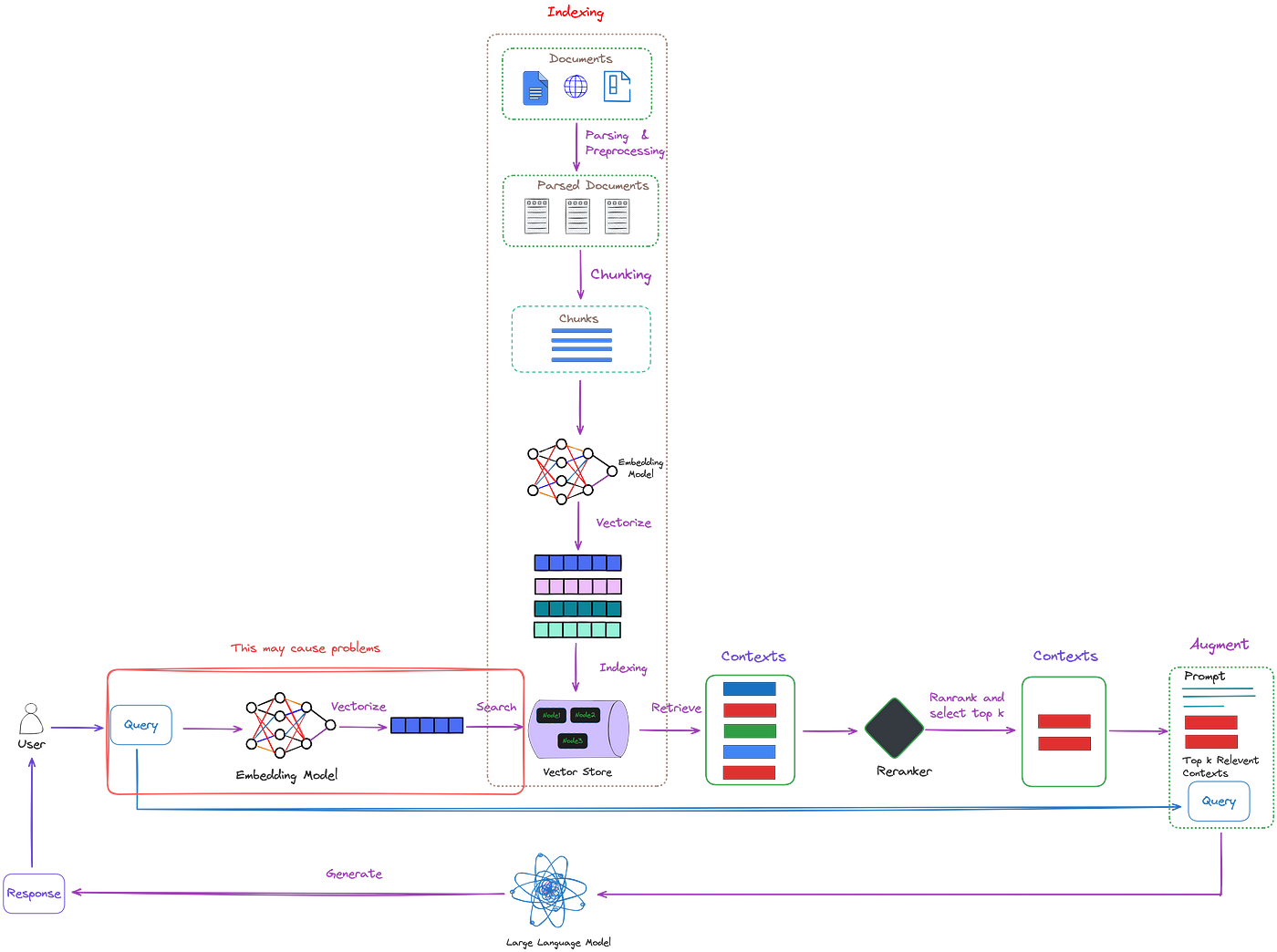
This approach may result in some potential problems, such as:
This system may consume excessive computing resources to handle simple queries.
For complex queries, simply retrieving with the original query often fails to gather sufficient information.
For ambiguous queries that could have multiple answers, using the original query for information retrieval proves insufficient.
This article will introduce two advanced solutions, query classification and query refinement. Both have shown improvements through the training of small models. Lastly, the article will discuss insights and thoughts obtained from these two algorithms.
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
Overall Process
Adaptive-RAG introduces a new adaptive framework. As shown in Figure 2, it dynamically chooses the most appropriate strategy for LLM, ranging from the simplest to the most complex, based on the query’s complexity.
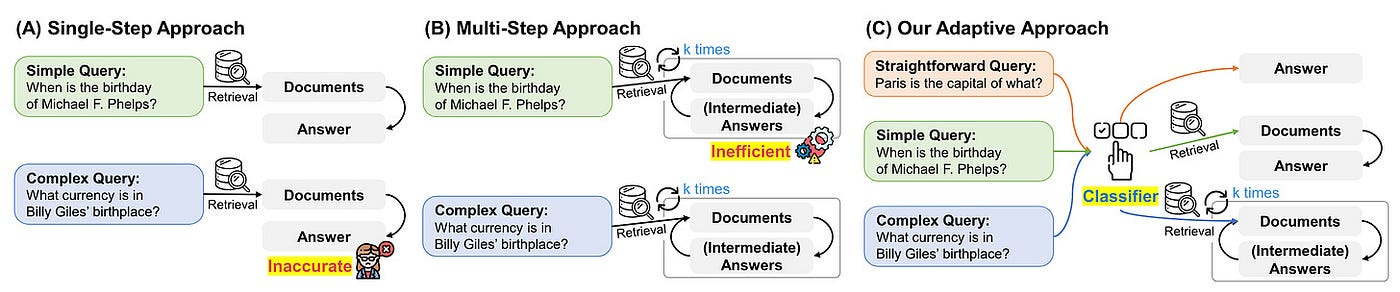
Figure 2 (A) represents a single-step approach where the relevant documents are first retrieved, followed by the generation of the answer. However, this method might not be sufficiently accurate for complex queries that require multi-step reasoning.
Figure 2 (B) symbolizes a multi-step process that involves iterative document retrieval and generation of intermediate responses. Despite its effectiveness, it’s inefficient for simple queries as it requires multiple accesses to both LLMs and retrievers.
Figure 2 (C) is an adaptive approach that determines query complexity using meticulously constructed classifiers. This enhances the selection of the most suitable strategy for LLM retrieval, which could include iterative, single, or even no retrieval methods.
For a more intuitive understanding of the Adaptive-RAG process, we’ll explain it in conjunction with the code. There are currently four versions of the code: the official version, Langchain version, LlamaIndex version, and Cohere version. We’ll use the LlamaIndex version for our explanation.
For details, refer to this Jupyter Notebook. The code is quite long, so only the key parts are discussed here.

The code’s operation depends on the query’s complexity, invoking different tools accordingly:
For complex queries: multiple tools are utilized. These tools require context from multiple documents, as depicted in the upper right of Figure 3.
For simple queries: a lone tool is used, requiring context from a single document, as illustrated in the upper left of Figure 3.
For straightforward queries: The LLM is directly used to provide the answer, as displayed at the bottom of Figure 3.
As indicated in Figure 2 (C), the tool is selected via the classifier. Contrary to the original paper, the classifier used here is not trained. Instead, it directly utilizes the pre-existing LLM, as depicted in Figure 4.

Construction of the Classifier
While the LlamaIndex code does not include a classifier training process, understanding the construction process of the classifier is crucial for our further development.
Construction of the Dataset
A key challenge is the lack of an annotated dataset for query-complexity pairs. How to address this? Adaptive-RAG employs two specific strategies to automatically construct the training dataset.
The dataset provided by Adaptive-RAG reveals that the labeling of classifier training data is based on publicly labeled QA datasets.
There are two strategies:
Regarding the collected questions, if the simplest non-retrieval based method generates the correct answer, the label for its corresponding query is marked as ‘
A’. Likewise, queries that are correctly answered by the single-step method are labeled ‘B’, while those answered correctly by the multi-step method are labeled ‘C’. It worth mention that simpler models are given higher priorities. This means, if both single-step and multi-step methods yield the correct result and the non-retrieval-based method fails, we will assign the label ‘B’ to its corresponding query, as illustrated in Figure 5.
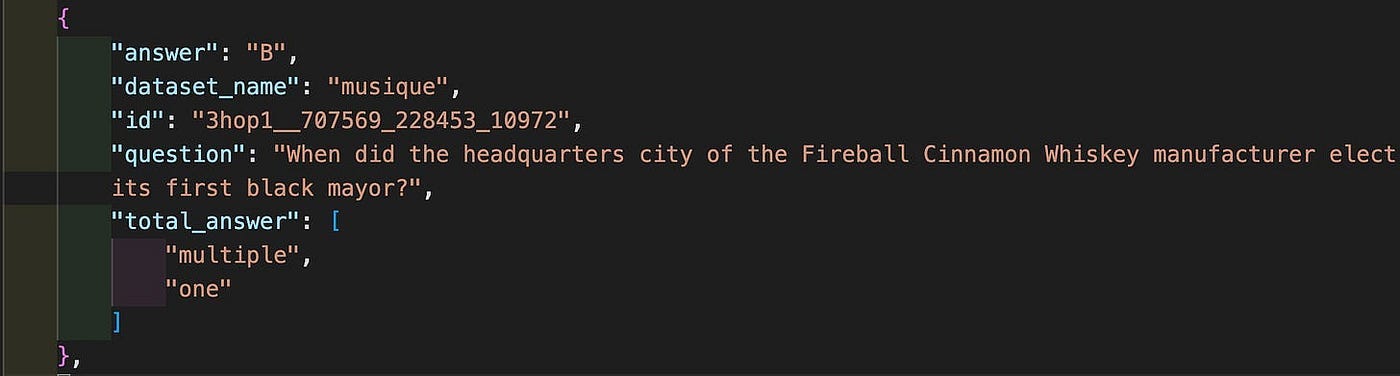
If all three methods fail to generate the correct answer, it indicates that some questions remain untagged. In this case, allocation is performed directly from the public dataset. Specifically, we assign ‘
B’ to queries in the single-hop dataset, and ‘C’ to queries in the multi-hop dataset.
Training and Inference
The training method involves using cross-entropy loss to train the classifier based on these automatically collected query-complexity pairs.
Then, during inference, we can determine the complexity of the query, which is one of {‘A’, ‘B’, ‘C’}, by forwarding it to the classifier: o = Classifier(q).
Selection of Classifier Size

As illustrated in Figure 6, there is no significant performance difference between classifiers of varying sizes. Even a smaller model does not impact performance, thereby aiding in resource efficiency.
Next, we will introduce a query refinement method: RQ-RAG.
RQ-RAG: Learning To Refine Queries For Retrieval Augmented Generation
In response to the mentioned challenges, RQ-RAG has proposed three improvements, as depicted in Figure 7.
Keep reading with a 7-day free trial
Subscribe to AI Exploration Journey to keep reading this post and get 7 days of free access to the full post archives.