


Advanced RAG 05: Exploring Semantic Chunking
Introducing principles and applications of semantic chunking

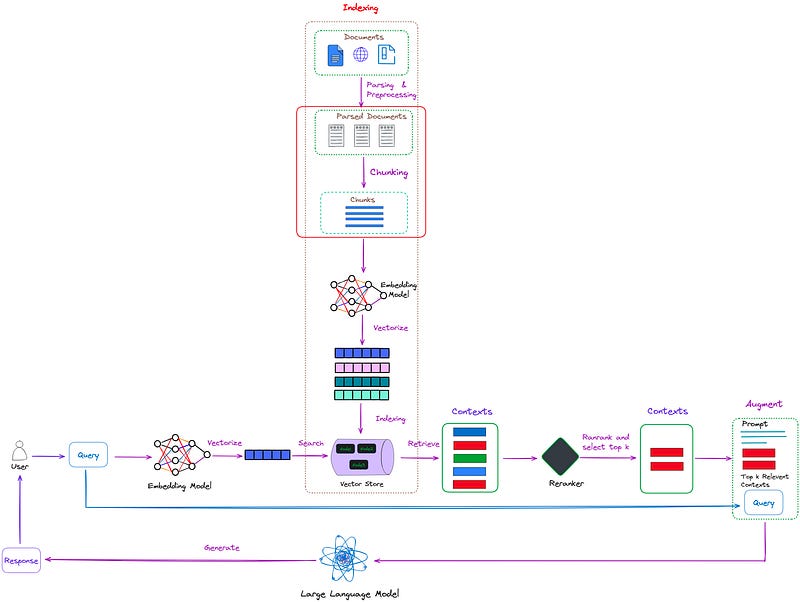
After parsing the document, we can obtain structured or semi-structured data. The main task now is to break them down into smaller chunks to extract detailed features, and then embed these features to represent their semantics. Its position in RAG is shown in Figure 1.
Most commonly used chunking methods are rule-based, employing techniques such as fixed chunk size or overlap of adjacent chunks. For multi-level documents, we can use RecursiveCharacterTextSplitter provided by Langchain. This allows for the definition of multi-level separators.
However, in practical applications, due to the rigid predefined rules (chunk size or size of overlapping parts), rule-based chunking methods can easily lead to problems such as incomplete retrieval contexts or excessive chunk size containing noise.
Therefore, for chunking, the most elegant method is obviously to chunk based on semantics. Semantic chunking aims to ensure that each chunk contains as much semantically independent information as possible.
This article explores the methods of semantic chunking, explaining their principles and applications. We will introduce three types of methods:
Embedding-based
Model-based
LLM-based
Embedding-based methods
Both LlamaIndex and Langchain provide a semantic chunker based on embedding. The idea of the algorithm is more or less the same, we will use LlamaIndex as an example for explanation.
Please note that to access the semantic chunker in LlamaIndex, you’ll need to install a more recent version. The previous version I installed, 0.9.45, didn’t include this algorithm. As a result, I created a new conda environment and installed the updated version, 0.10.12:
pip install llama-index-core
pip install llama-index-readers-file
pip install llama-index-embeddings-openaiIt’s worth mentioning that LlamaIndex’s 0.10.12 can be installed flexibly, so only some key components are installed here. The installed versions are as follows:
(llamaindex_010) Florian:~ Florian$ pip list | grep llama
llama-index-core 0.10.12
llama-index-embeddings-openai 0.1.6
llama-index-readers-file 0.1.5
llamaindex-py-client 0.1.13The test code is as follows:
from llama_index.core.node_parser import (
SentenceSplitter,
SemanticSplitterNodeParser,
)
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import SimpleDirectoryReader
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
# load documents
dir_path = "YOUR_DIR_PATH"
documents = SimpleDirectoryReader(dir_path).load_data()
embed_model = OpenAIEmbedding()
splitter = SemanticSplitterNodeParser(
buffer_size=1, breakpoint_percentile_threshold=95, embed_model=embed_model
)
nodes = splitter.get_nodes_from_documents(documents)
for node in nodes:
print('-' * 100)
print(node.get_content())I traced the splitter.get_nodes_from_documents function, and its primary process is depicted in Figure 2:
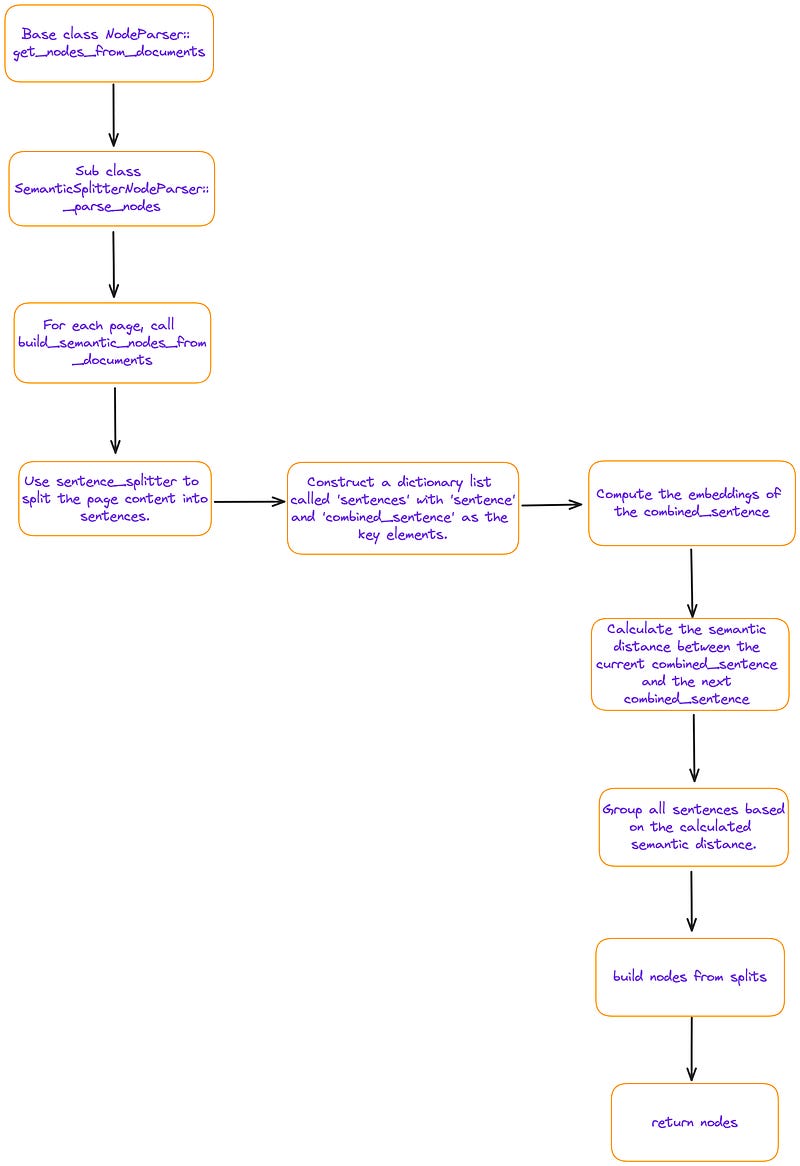
splitter.get_nodes_from_documents function. Image by author.The “sentences” mentioned in Figure 2 is a python list, each member of which is a dictionary containing four (key, value) pairs, , the meanings of the keys are as follows:
sentence: The current sentenceindex: The sequence number of the current sentencecombined_sentence: A sliding window, including[index -self.buffer_size, index, index + self.buffer_size]3 sentences(by default,self.buffer_size = 1). It is a tool used to calculate the semantic relevance between sentences. The aim of combining preceding and succeeding sentences is to decrease noise and better capture the relationships between sequential sentences.combined_sentence_embedding: The embedding of the combined_sentence
From the above analysis, it’s evident that semantic chunking based on embedding essentially involves calculating similarity based on a sliding window(combined_sentence). Those sentences that are adjacent and meet the threshold are classified into one chunk.
The directory path only contains one BERT paper document. Here are some of the running results:
(llamaindex_010) Florian:~ Florian$ python /Users/Florian/Documents/june_pdf_loader/test_semantic_chunk.py
...
...
----------------------------------------------------------------------------------------------------
We argue that current techniques restrict the
power of the pre-trained representations, espe-
cially for the fine-tuning approaches. The ma-
jor limitation is that standard language models are
unidirectional, and this limits the choice of archi-
tectures that can be used during pre-training. For
example, in OpenAI GPT, the authors use a left-to-
right architecture, where every token can only at-
tend to previous tokens in the self-attention layers
of the Transformer (Vaswani et al., 2017). Such re-
strictions are sub-optimal for sentence-level tasks,
and could be very harmful when applying fine-
tuning based approaches to token-level tasks such
as question answering, where it is crucial to incor-
porate context from both directions.
In this paper, we improve the fine-tuning based
approaches by proposing BERT: Bidirectional
Encoder Representations from Transformers.
BERT alleviates the previously mentioned unidi-
rectionality constraint by using a “masked lan-
guage model” (MLM) pre-training objective, in-
spired by the Cloze task (Taylor, 1953). The
masked language model randomly masks some of
the tokens from the input, and the objective is to
predict the original vocabulary id of the maskedarXiv:1810.04805v2 [cs.CL] 24 May 2019
----------------------------------------------------------------------------------------------------
word based only on its context. Unlike left-to-
right language model pre-training, the MLM ob-
jective enables the representation to fuse the left
and the right context, which allows us to pre-
train a deep bidirectional Transformer. In addi-
tion to the masked language model, we also use
a “next sentence prediction” task that jointly pre-
trains text-pair representations. The contributions
of our paper are as follows:
• We demonstrate the importance of bidirectional
pre-training for language representations. Un-
like Radford et al. (2018), which uses unidirec-
tional language models for pre-training, BERT
uses masked language models to enable pre-
trained deep bidirectional representations. This
is also in contrast to Peters et al.
----------------------------------------------------------------------------------------------------
...
...Embedding-based methods: Summary
The test results indicate that the chunk’s granularity is relatively coarse.
Figure 2 also shows that this method is page-based and doesn’t directly address the issue of chunks spanning multiple pages.
Generally, the performance of Embedding-based methods heavily relies on the embedding model. The actual effectiveness requires future evaluation.
Model-based methods
Naive BERT
Recall the pre-training process of BERT. A binary classification task, Next Sentence Prediction (NSP), was designed to teach the model the relationship between two sentences. Here, two sentences are input into BERT simultaneously, and the model predicts if the second sentence follows the first.
We can apply this principle to design a straightforward chunking method. For a document, split it into sentences. Then, use a sliding window to input two adjacent sentences into the BERT model for NSP judgement, as illustrated in Figure 3:

If the predicted score is below the preset threshold, it suggests a weak semantic relationship between the two sentences. This can serve as a text segmentation point, as illustrated between sentence 2 and sentence 3 in Figure 3.
The advantage of this method is that it can be used directly without the need for training or fine-tuning.
However, this method only considers the preceding and following sentences when determining a text segmentation point, neglecting information from further segments. Moreover, the prediction efficiency of this method is relatively low.
Cross Segment Attention
The paper Text Segmentation by Cross Segment Attention proposed three models about Cross Segment Attention, as shown in Figure 4:

Figure 4 (a) shows the cross-segment BERT model, which defines text segmentation as a sentence-by-sentence classification task. The context of the potential break (the k tokens on either side) is input into the model. The hidden state corresponding to [CLS] is passed to the softmax classifier to make decisions about segmenting at the potential break.
The paper also presents two additional models. One uses the BERT model to obtain vector representations of each sentence. These vector representations of multiple consecutive sentences are then input into an Bi-LSTM (Figure 4 (b)) or another BERT (Figure 4 (c)) to predict whether each sentence is a text segmentation boundary.
At that time, these three models achieved state-of-the-art results, as shown in Figure 5:

However, so far, only the training implementation from this paper has been discovered. No publicly available model for inference has been found.
SeqModel
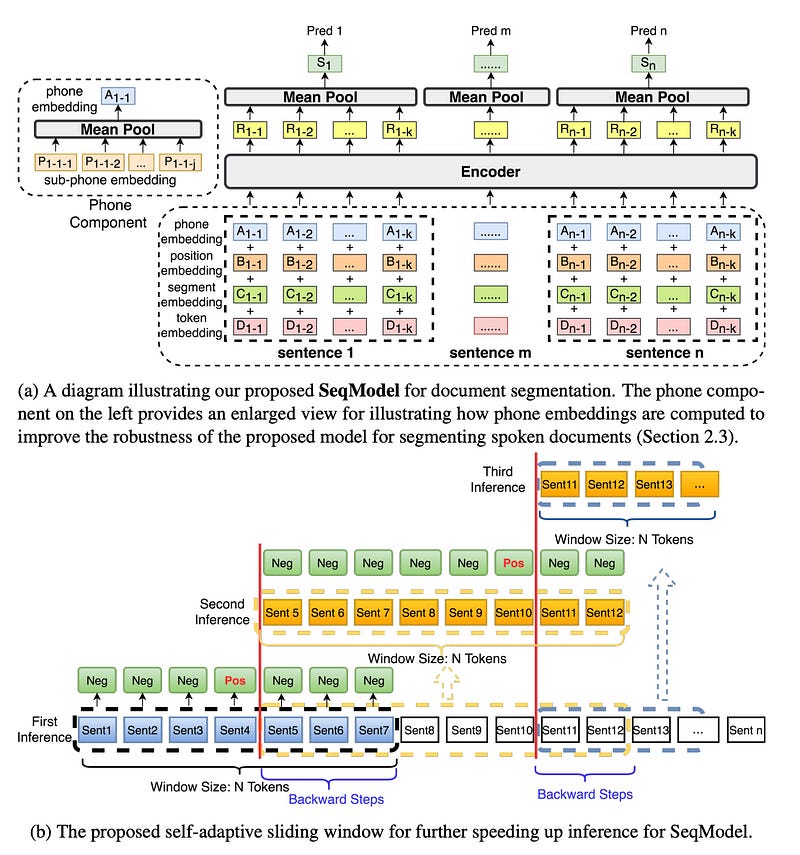
The Cross-Segment model vectorizes each sentence independently, not taking into account any broader contextual information. Further enhancements were proposed in the SeqModel, as detailed in the paper “Sequence Model with Self-Adaptive Sliding Window for Efficient Spoken Document Segmentation”.
SeqModel employs BERT to encode several sentences simultaneously, modeling dependencies within longer contexts before computing sentence vectors. It then predicts if text segmentation takes place after each sentence. Furthermore, this model utilizes the self-adaptive sliding window method to boost inference speed without compromising accuracy. A schematic diagram of SeqModel is shown in Figure 6.
SeqModel can be used via the ModelScope Framework. The code is provided below:
from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
p = pipeline(
task = Tasks.document_segmentation,
model = 'damo/nlp_bert_document-segmentation_english-base'
)
print('-' * 100)
result = p(documents='We demonstrate the importance of bidirectional pre-training for language representations. Unlike Radford et al. (2018), which uses unidirectional language models for pre-training, BERT uses masked language models to enable pretrained deep bidirectional representations. This is also in contrast to Peters et al. (2018a), which uses a shallow concatenation of independently trained left-to-right and right-to-left LMs. • We show that pre-trained representations reduce the need for many heavily-engineered taskspecific architectures. BERT is the first finetuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many task-specific architectures. Today is a good day')
print(result[OutputKeys.TEXT])The test data appended a sentence, Today is a good day, at the end, but the result didn’t separate Today is a good day in any way.
(modelscope) Florian:~ Florian$ python /Users/Florian/Documents/june_pdf_loader/test_seqmodel.py
2024-02-24 17:09:36,288 - modelscope - INFO - PyTorch version 2.2.1 Found.
2024-02-24 17:09:36,288 - modelscope - INFO - Loading ast index from /Users/Florian/.cache/modelscope/ast_indexer
...
...
----------------------------------------------------------------------------------------------------
...
...
We demonstrate the importance of bidirectional pre-training for language representations.Unlike Radford et al.(2018), which uses unidirectional language models for pre-training, BERT uses masked language models to enable pretrained deep bidirectional representations.This is also in contrast to Peters et al.(2018a), which uses a shallow concatenation of independently trained left-to-right and right-to-left LMs.• We show that pre-trained representations reduce the need for many heavily-engineered taskspecific architectures.BERT is the first finetuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many task-specific architectures.Today is a good dayModel-based methods: Summary
Overall, there is still much room for enhancement in the model-based semantic chunking method.
One improvement method I suggest is to create project-specific training data for domain fine-tuning. This could enhance the performance of the model. In addition, optimizing the model architecture is also a point of improvement.
The model-based method remains effective if we can find a model performs well on specific business data.
LLM-based methods
The paper, Dense X Retrieval: What Retrieval Granularity Should We Use?, introduces a new unit of retrieval known as the proposition. Propositions are defined as atomic expressions within text, each encapsulating a distinct factoid and presented in a concise, self-contained natural language format.
So how do we obtain this so-called proposition? In the paper, it is achieved through the construction of prompts and interaction with the LLM.
Both LlamaIndex and Langchain have implemented the relevant algorithms, with the following demonstration using LlamaIndex.
The implementation idea for LlamaIndex involves using the prompt provided in the paper to generate propositions:
PROPOSITIONS_PROMPT = PromptTemplate(
"""Decompose the "Content" into clear and simple propositions, ensuring they are interpretable out of
context.
1. Split compound sentence into simple sentences. Maintain the original phrasing from the input
whenever possible.
2. For any named entity that is accompanied by additional descriptive information, separate this
information into its own distinct proposition.
3. Decontextualize the proposition by adding necessary modifier to nouns or entire sentences
and replacing pronouns (e.g., "it", "he", "she", "they", "this", "that") with the full name of the
entities they refer to.
4. Present the results as a list of strings, formatted in JSON.
Input: Title: ¯Eostre. Section: Theories and interpretations, Connection to Easter Hares. Content:
The earliest evidence for the Easter Hare (Osterhase) was recorded in south-west Germany in
1678 by the professor of medicine Georg Franck von Franckenau, but it remained unknown in
other parts of Germany until the 18th century. Scholar Richard Sermon writes that "hares were
frequently seen in gardens in spring, and thus may have served as a convenient explanation for the
origin of the colored eggs hidden there for children. Alternatively, there is a European tradition
that hares laid eggs, since a hare’s scratch or form and a lapwing’s nest look very similar, and
both occur on grassland and are first seen in the spring. In the nineteenth century the influence
of Easter cards, toys, and books was to make the Easter Hare/Rabbit popular throughout Europe.
German immigrants then exported the custom to Britain and America where it evolved into the
Easter Bunny."
Output: [ "The earliest evidence for the Easter Hare was recorded in south-west Germany in
1678 by Georg Franck von Franckenau.", "Georg Franck von Franckenau was a professor of
medicine.", "The evidence for the Easter Hare remained unknown in other parts of Germany until
the 18th century.", "Richard Sermon was a scholar.", "Richard Sermon writes a hypothesis about
the possible explanation for the connection between hares and the tradition during Easter", "Hares
were frequently seen in gardens in spring.", "Hares may have served as a convenient explanation
for the origin of the colored eggs hidden in gardens for children.", "There is a European tradition
that hares laid eggs.", "A hare’s scratch or form and a lapwing’s nest look very similar.", "Both
hares and lapwing’s nests occur on grassland and are first seen in the spring.", "In the nineteenth
century the influence of Easter cards, toys, and books was to make the Easter Hare/Rabbit popular
throughout Europe.", "German immigrants exported the custom of the Easter Hare/Rabbit to
Britain and America.", "The custom of the Easter Hare/Rabbit evolved into the Easter Bunny in
Britain and America." ]
Input: {node_text}
Output:"""
)In the previous section Embedding-based methods, we have installed key components of LlamaIndex 0.10.12. But if we want to use DenseXRetrievalPack, we also need to run pip install llama-index-llms-openai. After the installation, the current LlamaIndex related components are as follows:
(llamaindex_010) Florian:~ Florian$ pip list | grep llama
llama-index-core 0.10.12
llama-index-embeddings-openai 0.1.6
llama-index-llms-openai 0.1.6
llama-index-readers-file 0.1.5
llamaindex-py-client 0.1.13In LlamaIndex, DenseXRetrievalPack is a pack that needs to be downloaded separately. Here it is directly downloaded in the test code. The test code is as follows:
from llama_index.core.readers import SimpleDirectoryReader
from llama_index.core.llama_pack import download_llama_pack
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
# Download and install dependencies
DenseXRetrievalPack = download_llama_pack(
"DenseXRetrievalPack", "./dense_pack"
)
# If you have already downloaded DenseXRetrievalPack, you can import it directly.
# from llama_index.packs.dense_x_retrieval import DenseXRetrievalPack
# Load documents
dir_path = "YOUR_DIR_PATH"
documents = SimpleDirectoryReader(dir_path).load_data()
# Use LLM to extract propositions from every document/node
dense_pack = DenseXRetrievalPack(documents)
response = dense_pack.run("YOUR_QUERY")Through the test code, it can be found that the constructor of class DenseXRetrievalPack is primarily in use. Analyzing the source code of the class DenseXRetrievalPack appears necessary.
class DenseXRetrievalPack(BaseLlamaPack):
def __init__(
self,
documents: List[Document],
proposition_llm: Optional[LLM] = None,
query_llm: Optional[LLM] = None,
embed_model: Optional[BaseEmbedding] = None,
text_splitter: TextSplitter = SentenceSplitter(),
similarity_top_k: int = 4,
) -> None:
"""Init params."""
self._proposition_llm = proposition_llm or OpenAI(
model="gpt-3.5-turbo",
temperature=0.1,
max_tokens=750,
)
embed_model = embed_model or OpenAIEmbedding(embed_batch_size=128)
nodes = text_splitter.get_nodes_from_documents(documents)
sub_nodes = self._gen_propositions(nodes)
all_nodes = nodes + sub_nodes
all_nodes_dict = {n.node_id: n for n in all_nodes}
service_context = ServiceContext.from_defaults(
llm=query_llm or OpenAI(),
embed_model=embed_model,
num_output=self._proposition_llm.metadata.num_output,
)
self.vector_index = VectorStoreIndex(
all_nodes, service_context=service_context, show_progress=True
)
self.retriever = RecursiveRetriever(
"vector",
retriever_dict={
"vector": self.vector_index.as_retriever(
similarity_top_k=similarity_top_k
)
},
node_dict=all_nodes_dict,
)
self.query_engine = RetrieverQueryEngine.from_args(
self.retriever, service_context=service_context
)As shown in the code, the constructor’s idea is to initially divide the document into original nodes using text_splitter, and then invoke self._gen_propositions to obtain the corresponding sub_nodes by generating propositions. It then builds a VectorStoreIndex using nodes + sub_nodes, which can be retrieved via RecursiveRetriever. A recursive retriever can retrieve using small chunks, but it passes associated larger chunks to the generation stage.
The directory path only contains one BERT paper document. Through debugging, we find that the sub_nodes[].text are not the original text, they have been rewritten:
> /Users/Florian/anaconda3/envs/llamaindex_010/lib/python3.11/site-packages/llama_index/packs/dense_x_retrieval/base.py(91)__init__()
90
---> 91 all_nodes = nodes + sub_nodes
92 all_nodes_dict = {n.node_id: n for n in all_nodes}
ipdb> sub_nodes[20]
IndexNode(id_='ecf310c7-76c8-487a-99f3-f78b273e00d9', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={}, text='Our paper demonstrates the importance of bidirectional pre-training for language representations.', start_char_idx=None, end_char_idx=None, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n', index_id='8deca706-fe97-412c-a13f-950a19a594d1', obj=None)
ipdb> sub_nodes[21]
IndexNode(id_='4911332e-8e30-47d8-a5bc-ed7cbaa8e042', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={}, text='Radford et al. (2018) uses unidirectional language models for pre-training.', start_char_idx=None, end_char_idx=None, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n', index_id='8deca706-fe97-412c-a13f-950a19a594d1', obj=None)
ipdb> sub_nodes[22]
IndexNode(id_='83aa82f8-384a-4b06-92c8-d6277c4162bf', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={}, text='BERT uses masked language models to enable pre-trained deep bidirectional representations.', start_char_idx=None, end_char_idx=None, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n', index_id='8deca706-fe97-412c-a13f-950a19a594d1', obj=None)
ipdb> sub_nodes[23]
IndexNode(id_='2ac635c2-ccb0-4e62-88c7-bcbaef3ef38a', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={}, text='Peters et al. (2018a) uses a shallow concatenation of independently trained left-to-right and right-to-left LMs.', start_char_idx=None, end_char_idx=None, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n', index_id='8deca706-fe97-412c-a13f-950a19a594d1', obj=None)
ipdb> sub_nodes[24]
IndexNode(id_='e37b17cf-30dd-4114-a3c5-9921b8cf0a77', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={}, text='Pre-trained representations reduce the need for many heavily-engineered task-specific architectures.', start_char_idx=None, end_char_idx=None, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n', index_id='8deca706-fe97-412c-a13f-950a19a594d1', obj=None)The relationship between sub_nodes and nodes is depicted in Figure 7, a small-to-big index structure is constructed.

The small-to-big index structure is built through self._gen_propositions, the code is as follows:
async def _aget_proposition(self, node: TextNode) -> List[TextNode]:
"""Get proposition."""
inital_output = await self._proposition_llm.apredict(
PROPOSITIONS_PROMPT, node_text=node.text
)
outputs = inital_output.split("\n")
all_propositions = []
for output in outputs:
if not output.strip():
continue
if not output.strip().endswith("]"):
if not output.strip().endswith('"') and not output.strip().endswith(
","
):
output = output + '"'
output = output + " ]"
if not output.strip().startswith("["):
if not output.strip().startswith('"'):
output = '"' + output
output = "[ " + output
try:
propositions = json.loads(output)
except Exception:
# fallback to yaml
try:
propositions = yaml.safe_load(output)
except Exception:
# fallback to next output
continue
if not isinstance(propositions, list):
continue
all_propositions.extend(propositions)
assert isinstance(all_propositions, list)
nodes = [TextNode(text=prop) for prop in all_propositions if prop]
return [IndexNode.from_text_node(n, node.node_id) for n in nodes]
def _gen_propositions(self, nodes: List[TextNode]) -> List[TextNode]:
"""Get propositions."""
sub_nodes = asyncio.run(
run_jobs(
[self._aget_proposition(node) for node in nodes],
show_progress=True,
workers=8,
)
)
# Flatten list
return [node for sub_node in sub_nodes for node in sub_node]For each original node, asynchronously call self._aget_proposition to get the LLM’s return inital_output through PROPOSITIONS_PROMPT, then get propositions based on inital_output and build TextNode. Finally, associate these TextNode with the original node, that is [IndexNode.from_text_node(n, node.node_id) for n in nodes] .
It is worth mentioning that the original paper uses propositions generated by LLM as training data to further fine-tune a text generation model. The text generation model is now publicly accessible. Interested readers can try it out.
LLM-based methods: Summary
In general, this chunking method, which uses LLM to construct propositions, has achieved a more refined chunk. It forms a small-to-big index structure with the original node, thus providing a novel idea for semantic chunking.
However, this kind of method relies on LLM, which is relatively costly.
If conditions permit, LLM-based methods can be consistently followed and monitored.
Conclusion
This article explores the principles and implementation methods of three types of semantic chunking methods, and provides some reviews.
In general, semantic chunking is a more elegant way, and it is a key point to optimize RAG.
If you’re interested in RAG, feel free to check out my other articles.
Finally, if there are any questions, please point out in the comments section.