
A Brief Introduction to RQ-RAG
Core Idea
In response to the mentioned challenges, RQ-RAG has proposed three improvements, as depicted in Figure 1.
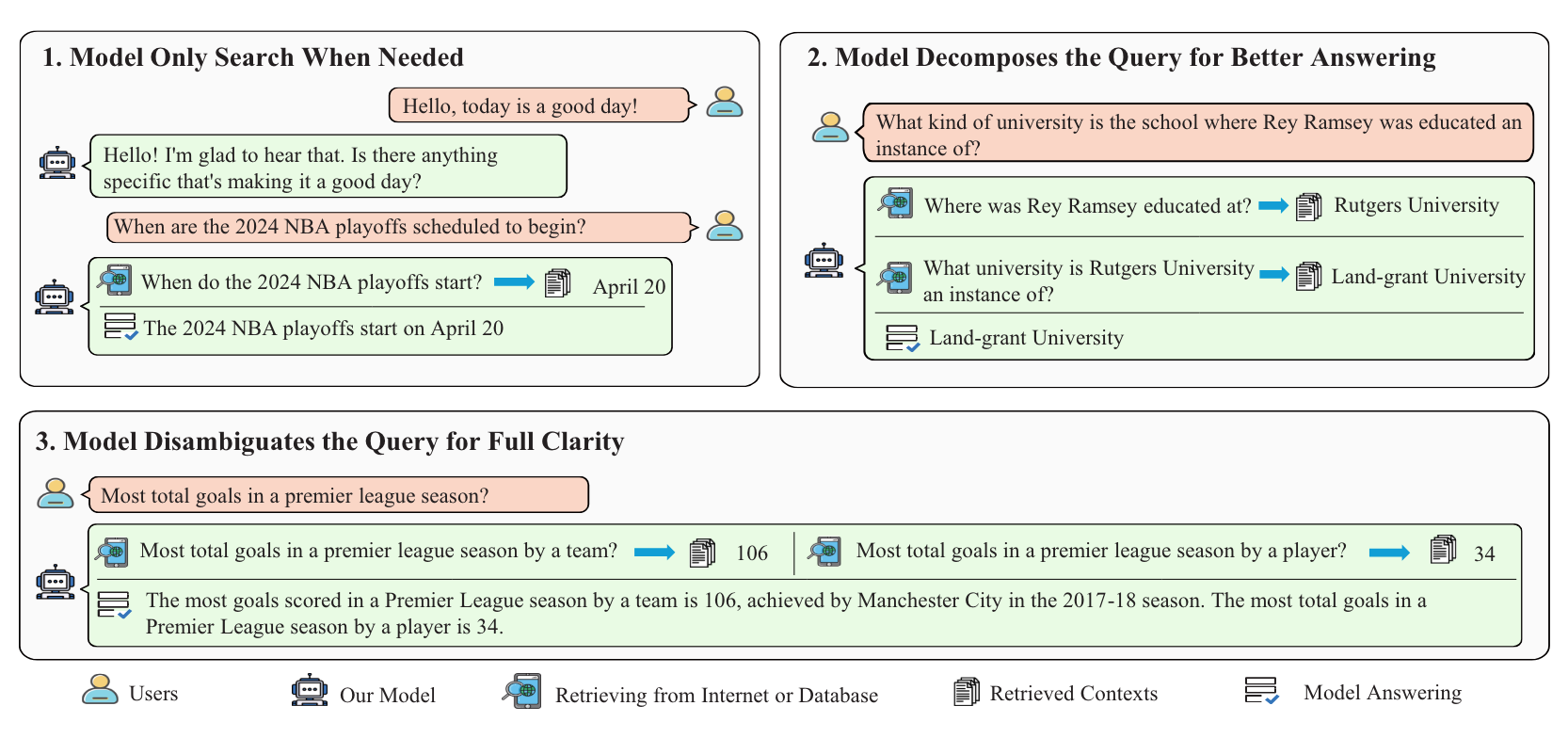
For simple inquiries, like daily greetings, introducing context can actually decrease the quality of the response. LLMs should respond directly instead of adding unnecessary context to avoid potential low-quality responses. In other words, the model should learn to respond on demand, as depicted in the top left of Figure 1.
For complex queries, they are divided into simpler, answerable subqueries. The corresponding information is then retrieved for each subquery, thereby forming a comprehensive response to the original complex query, as depicted in the top right of Figure 1.
For ambiguous queries with several potential responses, simply using the initial query statement for retrieval isn't sufficient. LLMs must learn to clarify queries, discern user intentions, and then devise specific search strategies. This approach helps retrieve comprehensive and precise information to answer questions, as depicted at the bottom of Figure 1.
How to implement RQ-RAG
From the core idea of RQ-RAG, it can be seen that the key to the algorithm is to classify and refine the query.
RQ-RAG's approach involves training a Llama2 7B model in an end-to-end manner. This enables the model to dynamically enhance search queries by rewriting, decomposing, and clarifying ambiguities.
Since the code of RQ-RAG is currently being refactored, some parts are not yet operational. Therefore, a demonstration won't be provided here.
Dataset construction
Given its end-to-end nature, it's crucial to focus on the strategy for data construction.
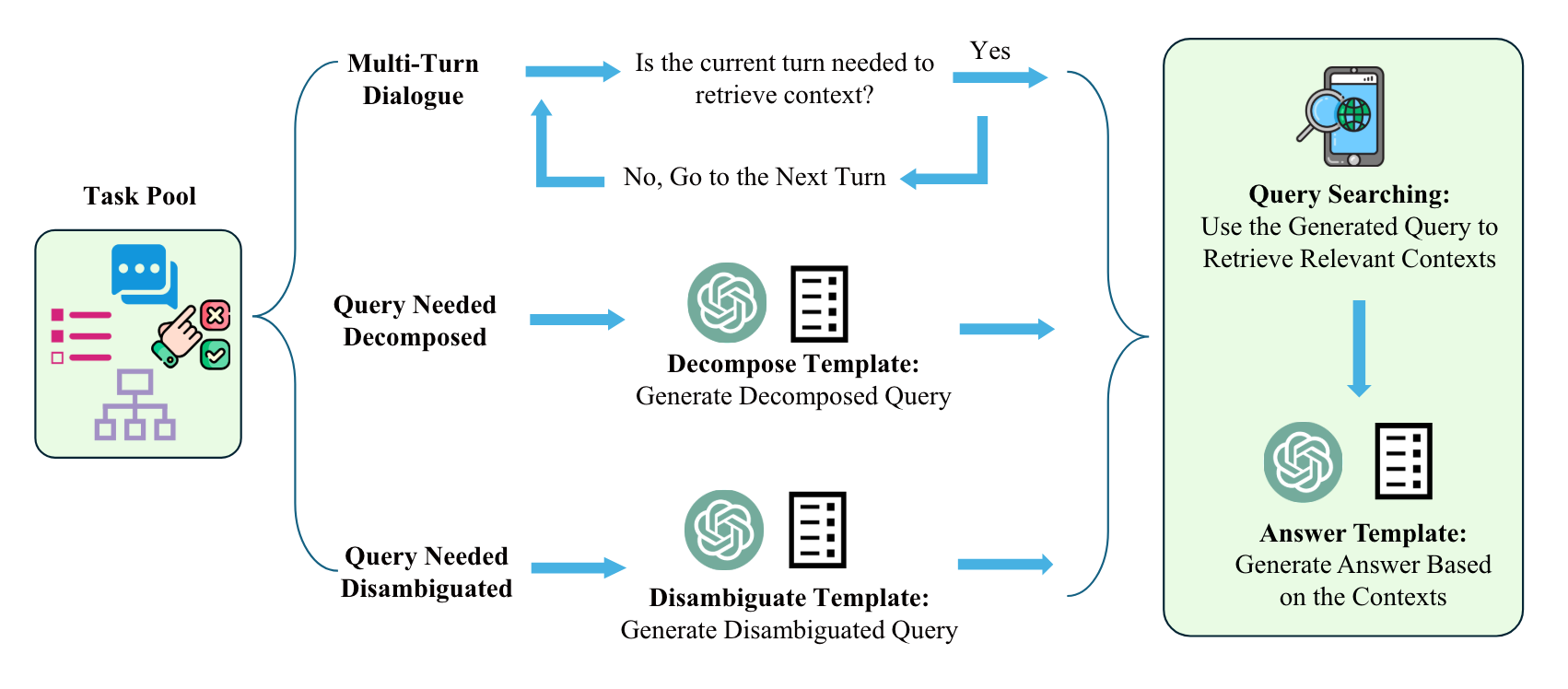
The construction of the dataset mainly consists of the following steps:
Collect a corpus, as illustrated in Figure 3, that includes various scenarios including multi-turn dialogues, queries that require decomposition, and queries that need disambiguation. Use this corpus to create a task pool.
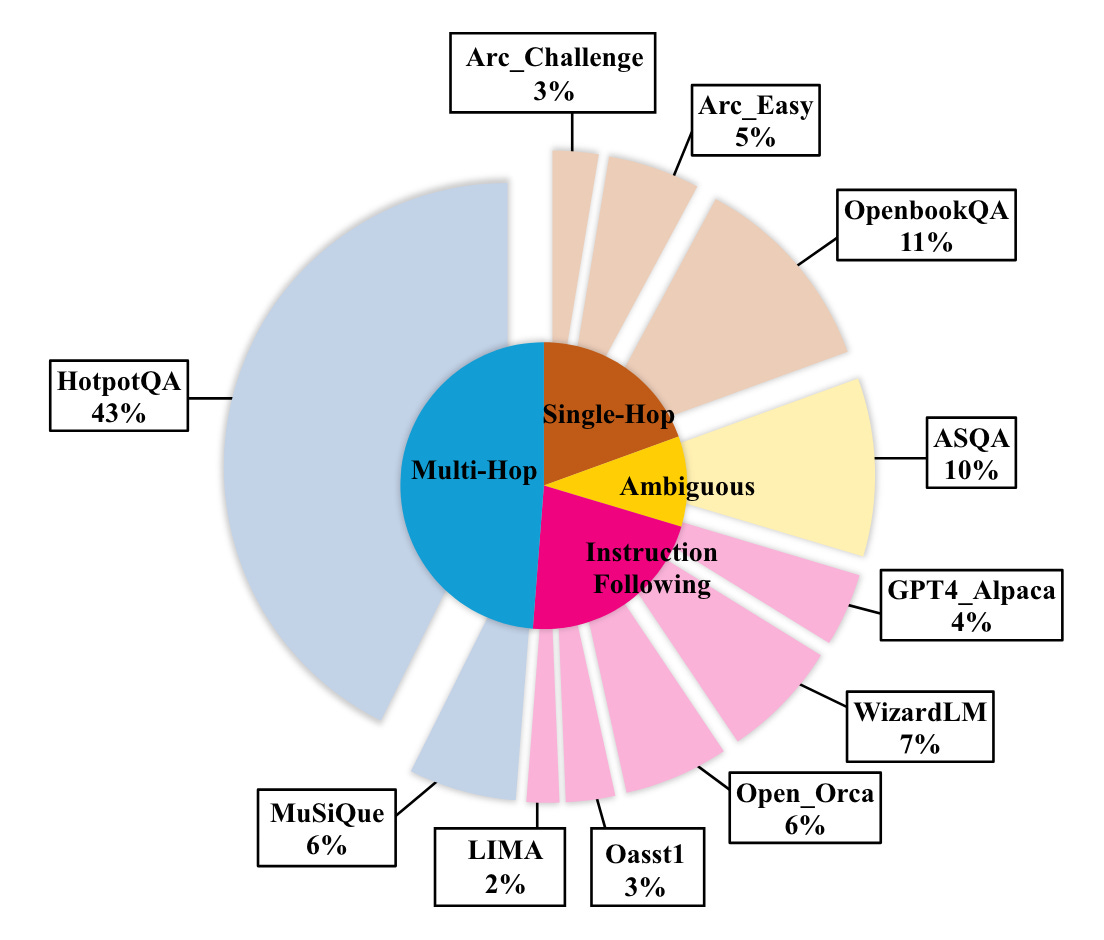
Figure 3: The composition of the dataset. Source: RQ-RAG. The tasks in the task pool are divided into three categories: multi-turn dialogue, decomposition, and disambiguation. For instance, samples in a multi-turn dialogue dataset are classified under the multi-turn dialogue category.
First, use ChatGPT to refine each type of query. Then, use these refined queries to retrieve information from external data sources. Usually, DuckDuckGo is the primary source, and the retrieval process is treated as a black box.
Next, prompt ChatGPT to generate a revised response based on the refined queries and their corresponding contexts. By repeating this process, you can amass a total of approximately 40k instances.
Figures 4, 5, and 6 display the prompt templates for interacting with ChatGPT. The blue text acts as a placeholder for specific inputs.



Once the above process is completed, we can obtain the training sample shown on the right side of Figure 7.
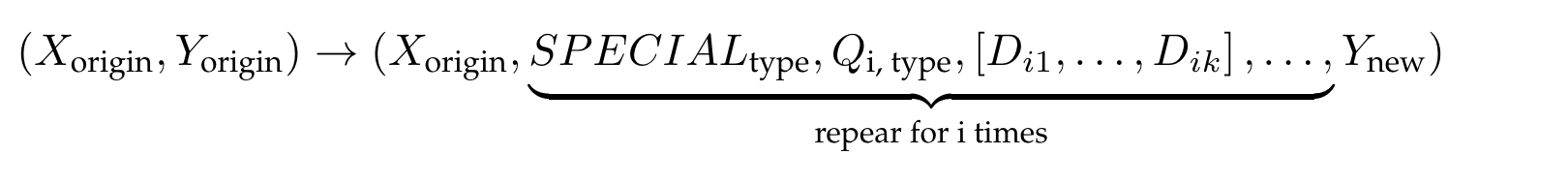
Each sample is an operation sequence with special tokens, where:
'Xorigin' and 'Yorigin' represent the input-output pair from the original dataset.
'Type' refers to the optimization action: rewrite, decompose, or eliminate ambiguity.
'i' refers to the round of iteration.
'SPECIALtype' represents the type of optimization.
'Qi, type' represents the query optimized according to the specific special tag in the i-th round.
'[Di1, Di2, . . . , Dik]' represents the top k documents retrieved in the i-th round.
'Ynew' represents a new answer generated in the final iteration step.
Training
After obtaining the training dataset, we can use it to train a LLM in a standard auto-regressive manner. The objective is as follows.
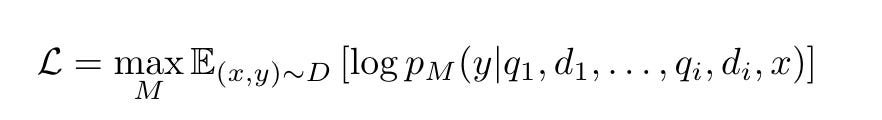
In simple terms, the objective of training is to adjust the model parameters so that at the i-th step, given the original input x, the enhanced query qi, and the retrieved document di, the model M should generate the highest probability for the response y.
Answer Selection
During each iteration, the model decodes diverse search queries customized for particular needs: rewriting, decomposing, or resolving ambiguities. These queries in turn obtain different contexts, leading to the diversification of expansion paths.
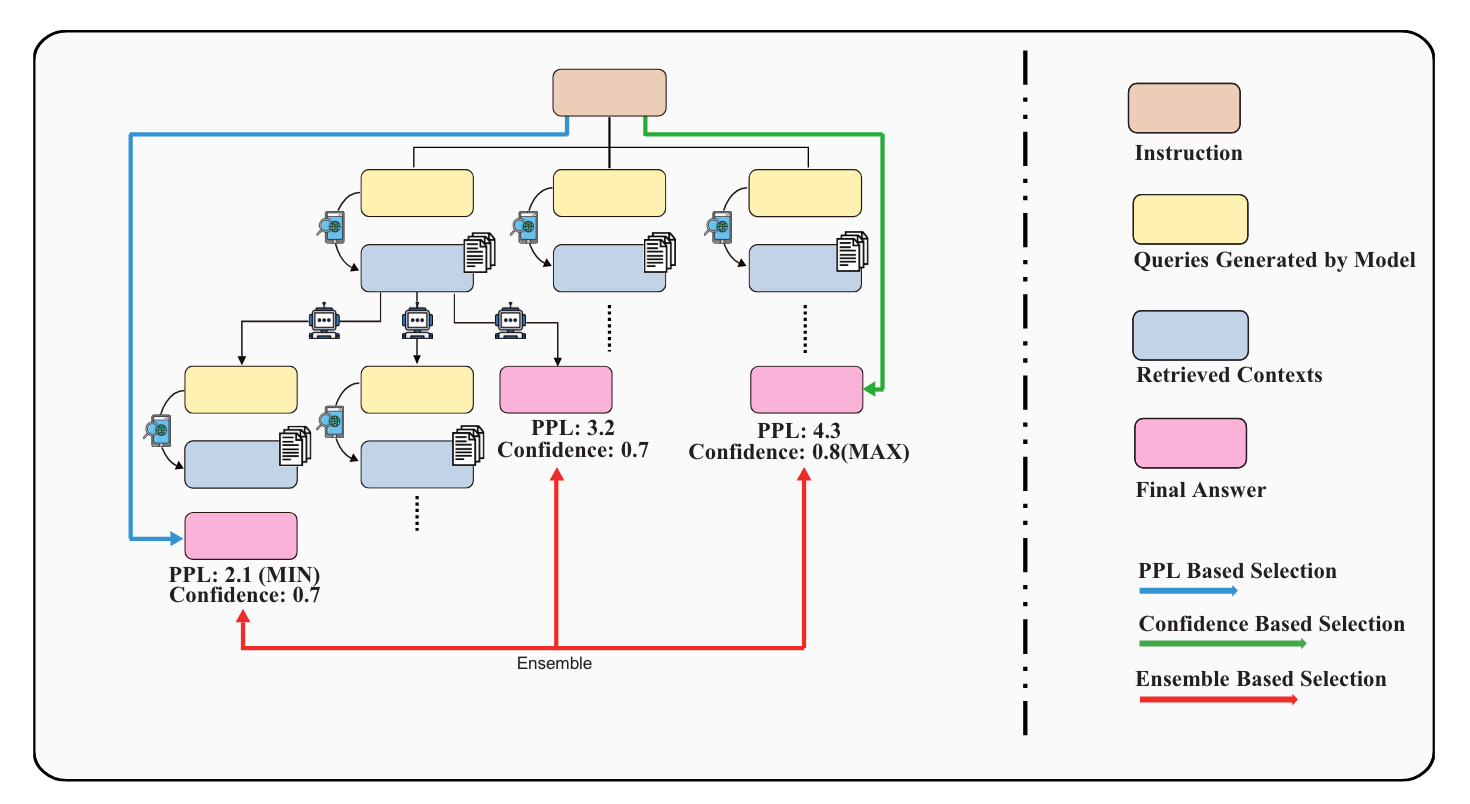
As illustrated in Figure 8, RQ-RAG has developed a tree decoding strategy and uses three selection methods: PPL Based Selection, Confidence Based Selection, and Ensemble Based Selection.
In PPL Based Selection, the answer with the lowest perplexity (PPL) from the total output is selected. Confidence Based Selection, on the other hand, chooses all results with the highest confidence. Lastly, Ensemble Based Selection selects the final result with the highest cumulative confidence score.